Engineering Database Interactions: Revisiting ORM-Repo-UoW Patterns
TLDR
Recently, I had to redo some database patterns in our application code and by default implemented arepo/uowpattern.
"Why not just use the ORM directly?", asked one the other engineers. I didn't have a good answer to that question other than a cookie cutter reply: "It's a proven pattern that will save us on technical debt..."... but was I so sure myself?
This post is my way to rethink this assumption and understand the patterns.
... Lets get on with it!
Raw SQL: Physical plumbing, connections and sessions.
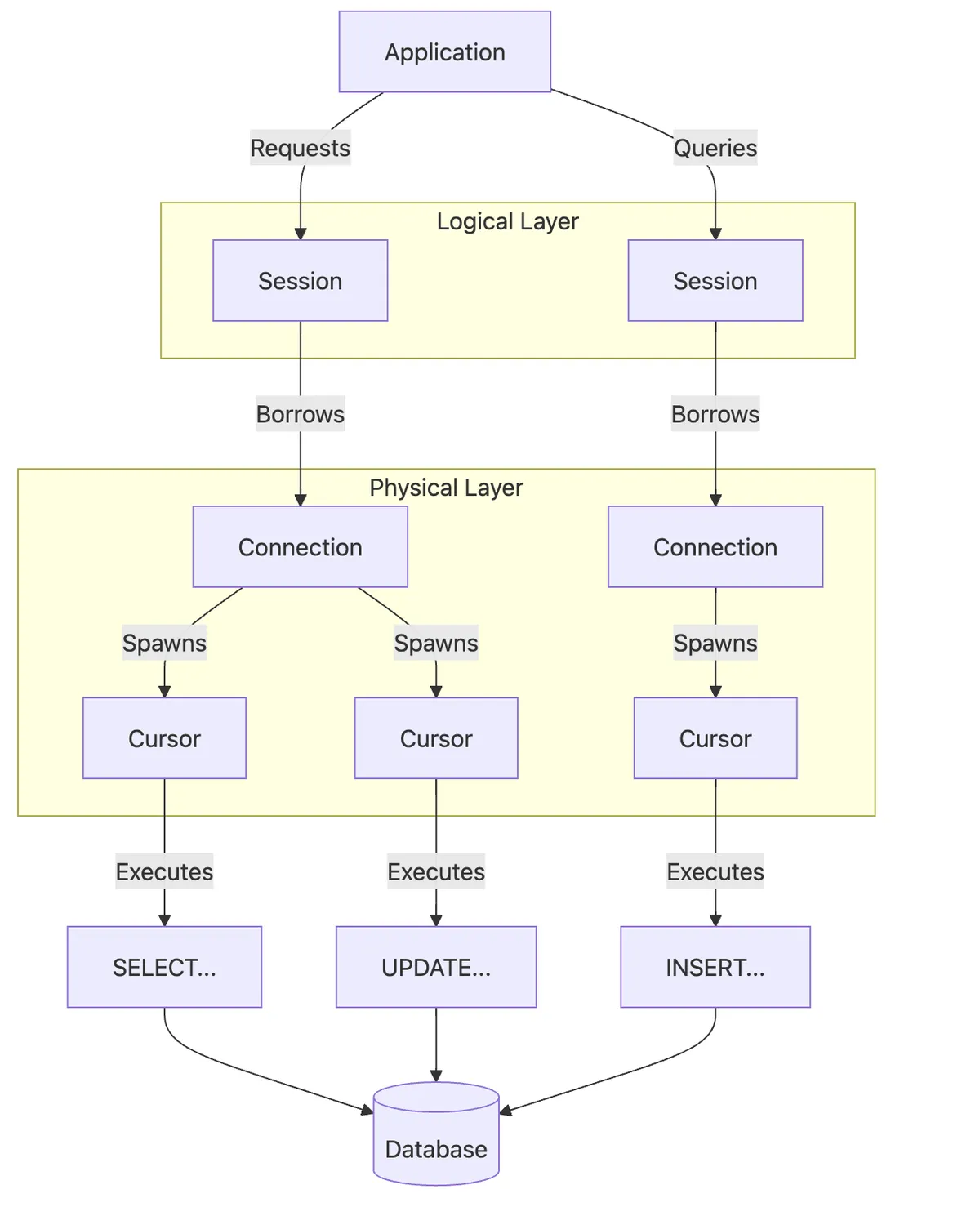
At the heart of database interactions lies the interaction of connection, cursor and session objects. Lets review:
Connection: The Database Hotline
A connection object represents an active connection to a database server and provides the foundation for all database interactions.
- It acts on the network level and creates a "pipe" for all transactions.
- No lunch is free: each connection consumes resources on both the application server and database server. Leaving connections open longer than necessary can lead to resource exhaustion.
- However, connections can be cheap to maintain once opened.
Key Attributes
isolation_level: Controls transaction isolation (e.g., 'READ UNCOMMITTED', 'READ COMMITTED', 'REPEATABLE READ', 'SERIALIZABLE')autocommit: Boolean flag determining if transactions are automatically committedclosed: Boolean indicating if the connection has been closed
Key Methods
cursor(): Creates and returns a new cursor object associated with this connectioncommit(): Commits the current transaction, making all changes permanentrollback(): Rolls back the current transaction, discarding all pending changesclose(): Closes the connection and releases resourcesexecute(): (Some implementations) Executes SQL directly without creating a cursorbegin(): Explicitly starts a new transaction (implementation varies)
Cursor: The SQL Commander
A cursor uses a connection. Cursors transform passive connections into stateful command channels - each maintains its own execution context like separate browser tabs.
Key Attributes
description: Returns metadata about columns in the result set (name, type, display size)rowcount: Number of rows affected by the last execute() (for DML statements)arraysize: Default number of rows to fetch with fetchmany()connection: Reference to the connection that created this cursor
Key Methods
execute(sql, params): Executes an SQL command, optionally with parameter substitutionexecutemany(sql, params_sequence): Executes the same SQL command against multiple parameter setsfetchone(): Retrieves the next row from the result setfetchmany(size): Retrieves the next batch of rowsfetchall(): Retrieves all remaining rowsclose(): Releases the cursor's resourcessetinputsizes(): Pre-defines memory areas for parameterssetoutputsize(): Sets buffer size for large column data
Session: The Bundler for Database Changes
A session provides a higher-level abstraction over connections and transactions. It acts as a logical container for related database operations that should be treated as a unit. Its like version control branches - all changes remain isolated until you commit the final PR, with automatic conflict detection via transaction isolation levels.
Key Attributes
active: Boolean indicating if the session is currently activedirty: Collection of objects that have been modified but not yet committednew:Collection of objects that have been added to the session but not yet committeddeleted:Collection of objects marked for deletionidentity_map: Dictionary mapping object identities to their in-memory instances
Key Methods
add(object): Registers an object to be inserted into the databasedelete(object): Marks an object for deletionquery(class): Constructs a query for retrieving objectscommit(): Persists all changes to the databaserollback(): Discards all pending changesclose(): Releases the session and its resourcesrefresh(object): Reloads an object's state from the databaseexpire(object): Marks an object as needing refresh before next access
To illustrate, here's a simplified system diagram showing their conceptual relationship:
And again in code:
import sqlite3
# Establish a connection to the Chinook database
conn = sqlite3.connect('chinook.db') cursor = conn.cursor()
# Test the connection with a simple query
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = cursor.fetchall()
print("Available tables:", tables)
# Always close connections when done
conn.close()
From the above, the basics are evident: connect, execute, close. Nice!
Now imagine this at scale: Each service or method that interacts with the database must manage its own connection. And its own SQL. And more. At scale, this will NOT turn out well.
Engineering For Robustness: The UoW & Repository Patterns
Focusing on application engineering with a reasonable amount of users, there are a few more considerations we have to carefully manage such as:
Resource Management
- Connection Management: In systems handling thousands of requests per minute, improper connection handling quickly exhausts database resources
- Transaction Coordination: Consider a banking transfer - debiting one account and crediting another must succeed or fail together
Data Integrity
- Concurrency Control: Multiple users attempting to update the same record simultaneously require careful handling
- Error Recovery: Systems must gracefully handle network failures, constraint violations, and other runtime issues
Security
- SQL Injection: Raw SQL is particularly susceptible to injection attacks if not properly parameterized
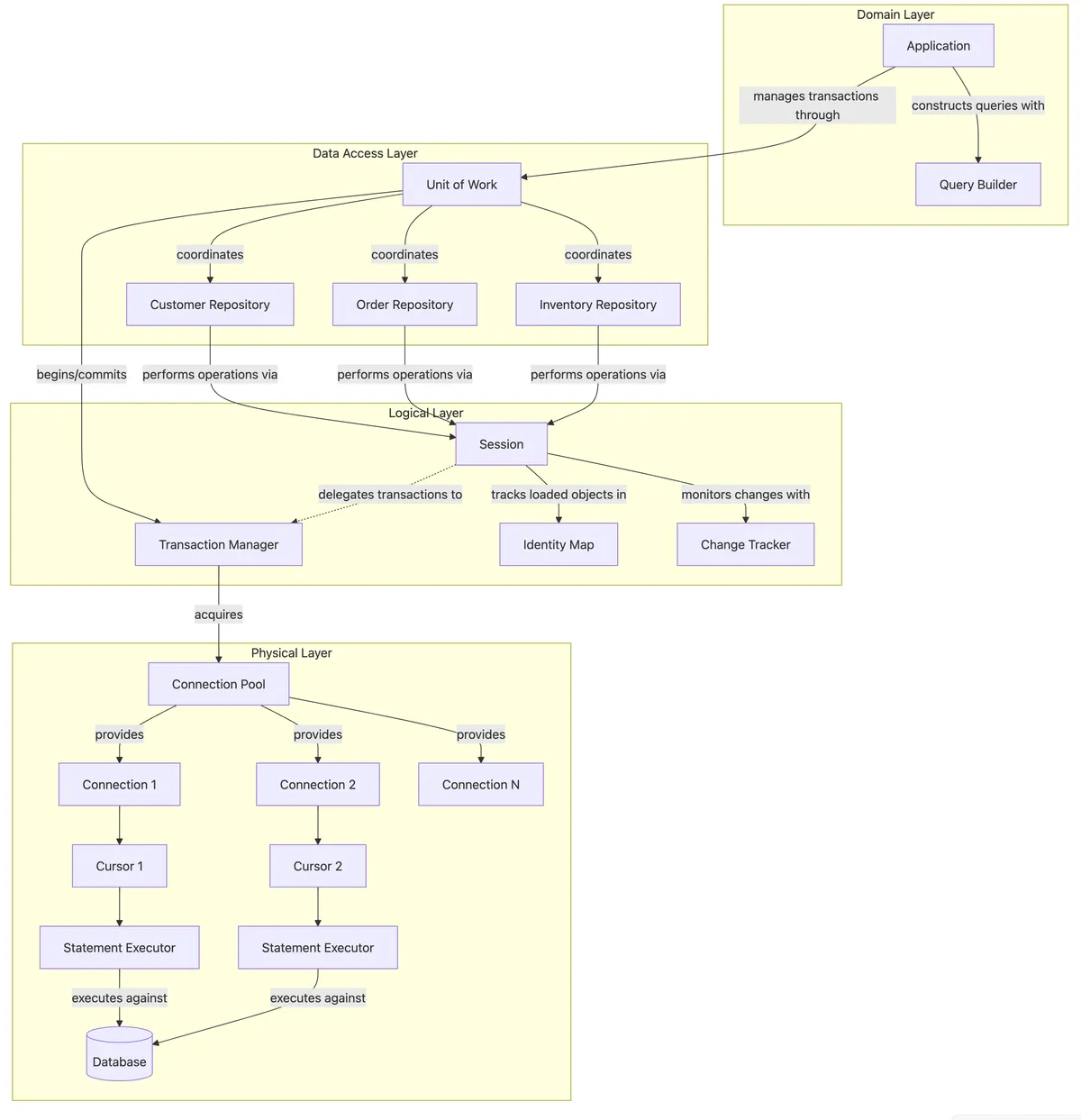
This is where the Unit of Work (UoW) and Repository patterns provide significant engineering benefits. These patterns introduce useful abstractions at the logical layer:
Unit of Work provides:
- Transaction Management: Ensures related operations succeed or fail as a unit
- Identity Map: Prevents the "lost update" problem by ensuring each entity is loaded just once per session
- Change Tracking: Efficiently identifies only the modified fields that need updating, reducing network traffic
Repository pattern delivers:
- Query Building: Enables dynamic query construction without string concatenation, eliminating SQL injection risks
- Domain-Database Separation: Isolates business logic from data access code
- Centralized Data Access: Standardizes how the application interacts with persistent storage
(For more details on this, check the # Deepdives below.)
Together, these patterns work with other components like Transaction Isolation Levels to balance data consistency with performance based on your application's needs.
Here's where the system architecture starts evolving to look something like this:
Lets make this relatable with some code and a real use case.
This example demonstrates transaction management using raw SQL. The BEGIN TRANSACTION statement initiates the transaction, COMMIT finalizes it, and ROLLBACK aborts it if errors occur. While functional, this approach requires explicit transaction management in every function that requires transactional integrity.
import sqlite3
from typing import Dict, Any, List, Optional
# Unit of Work pattern implementation
class CustomerUnitOfWork:
def __init__(self, db_path: str):
self.db_path = db_path
self.conn = None
self.customer_repository = None
def __enter__(self):
# Initialize connection when entering context
self.conn = sqlite3.connect(self.db_path)
self.conn.isolation_level = 'DEFERRED'
# Create repositories that share this connection
self.customer_repository = CustomerRepository(self.conn)
return self
def __exit__(self, exc_type, exc_val, exc_tb):
# Commit or rollback based on whether an exception occurred
try:
if exc_type is not None:
self.rollback()
else:
self.commit()
finally:
self.conn.close()
def commit(self):
self.conn.commit()
def rollback(self):
self.conn.rollback()
# Sample repository using the connection from UoW
class CustomerRepository:
def __init__(self, connection):
self.conn = connection
def get_by_id(self, customer_id: int) -> Optional[Dict[str, Any]]:
cursor = self.conn.cursor()
cursor.execute("SELECT * FROM customers WHERE CustomerId = ?", (customer_id,))
row = cursor.fetchone()
if not row:
return None
return {"CustomerId": row[0], "Email": row[1]} # simplified
def update_email(self, customer_id: int, new_email: str) -> bool:
cursor = self.conn.cursor()
cursor.execute(
"UPDATE customers SET Email = ? WHERE CustomerId = ?",
(new_email, customer_id)
)
return cursor.rowcount > 0
# Usage example
try:
# The Unit of Work manages transaction boundaries
with CustomerUnitOfWork('chinook.db') as uow:
# Multiple operations within a single transaction
customer = uow.customer_repository.get_by_id(1)
if customer:
uow.customer_repository.update_email(1, 'updated@example.com')
# No explicit commit needed - handled by context manager if no exceptions
except Exception as e:
print(f"Transaction failed: {e}")
With this approach, we've addressed several critical risks:
- Business Logic Failures: If inventory validation fails mid-transaction, the customer record update is rolled back
- Data Integrity: The transaction ensures our database remains consistent even during errors
- Resource Management: The finally block guarantees connection release regardless of execution path
- Isolation: Other users won't see partial updates while our transaction is in progress
However, even with these improvements, raw SQL transactions have significant limitations:
- Schema Coupling: Application code becomes tightly coupled to database structure, making schema evolution painful
- Code Duplication: Transaction handling logic must be repeated in every data access function
- Mixed Concerns: Business logic becomes intertwined with data access code, harming maintainability
- Testing Difficulty: Functions with direct SQL are harder to test without a live database
Fundamentally, while direct SQL interaction gives you complete control, it introduces several challenges that become more pronounced as applications grow in complexity. The tight coupling between application code and database schema makes it difficult to evolve the schema without breaking existing code. Also, SQL strings embedded throughout the codebase become difficult to maintain and test, and ensuring proper connection management across all database operations becomes increasingly error-prone.
This leads to our next pattern: ORMs, which maps OOP to SQL strings.
ORM: baking in the domain abstraction.
While the Unit of Work and Repository patterns bring significant improvements to raw SQL interactions, they still leave your application working with primitive data structures and manual SQL statement management. Not my idea of fun. This is where Object-Relational Mapping (ORM) frameworks help by providing a semantic approach to how we interact with databases.
I'll talk about SQLAlchemy as the implementation, but note there are many other flavours of ORMs out there like Prism for the JS/TS ecosystem. Back to SQLAlchemy: SQLAlchemy provides two distinct ways to interact with your database:
- Core: A SQL expression language that provides SQL construction objects
- ORM: A higher-level, object-oriented interface mapped to database tables
When using SQLAlchemy, it transforms how we work with our data access layer:

Let's see how this looks in practice with a concrete example:
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship
# Configuration and setup
engine = create_engine('sqlite:///chinook.db')
Base = declarative_base()
Session = sessionmaker(bind=engine)
# Domain model definitions
class Customer(Base):
__tablename__ = 'customers'
customer_id = Column(Integer, primary_key=True)
first_name = Column(String)
last_name = Column(String)
email = Column(String)
invoices = relationship("Invoice", back_populates="customer")
def __repr__(self):
return f"<Customer {self.first_name} {self.last_name}>"
class Invoice(Base):
__tablename__ = 'invoices'
invoice_id = Column(Integer, primary_key=True)
customer_id = Column(Integer, ForeignKey('customers.customer_id'))
invoice_date = Column(String)
total = Column(Integer)
customer = relationship("Customer", back_populates="invoices")
# Application code
session = Session()
# Query with relationships
customers_with_invoices = (
session.query(Customer)
.filter(Customer.invoices.any(Invoice.total > 10))
.order_by(Customer.last_name)
.all()
)
for customer in customers_with_invoices:
print(f"{customer.first_name} {customer.last_name} has purchased:")
for invoice in customer.invoices:
print(f" ${invoice.total:.2f} on {invoice.invoice_date}")
session.close()
By using the ORM approach, you get several significant engineering advantages:
- Domain-Driven Design Enablement: Work with meaningful business objects instead of rows and columns
- Relationship Mapping: Express complex object relationships naturally in code
- Database Vendor Independence: Switch between database engines with minimal code changes
- Lazy Loading Optimization: Retrieve related data only when accessed, reducing unnecessary queries
- Transaction Integration: Seamless integration with the UoW pattern built into the session
- Schema Evolution Support: Change database schema without breaking application code
- Type Safety: Move SQL errors from runtime to type-checking time
The Complete Picture: SQL databases via ORM, Repo, UoW
We now have 3 building blocks: an ORM, a Repo and a UoW. They each address different needs, resulting in a powerful matrix:
| Concern | Raw SQL | Repository | ORM |
|---|---|---|---|
| Schema Changes | Break all SQL | Update one class | Migrations + ORM |
| Query Safety | String hacking | Parameterization | Type-safe DSL |
| Connection Life | Manual | Pool per request | Session context |
Mixing and matching is totally valid, and you can:
- Use SQLAlchemy ORM directly for simple applications,
- Layer the Repository pattern on top of SQLAlchemy for cleaner domain separation
- Apply the Unit of Work pattern (which SQLAlchemy's session already implements internally... but explicit is better than implicit)
For large, complex systems, a common approach combines all three:
# Repository pattern with SQLAlchemy ORM
class CustomerRepository:
def __init__(self, session):
self.session = session
def get_by_id(self, customer_id):
return self.session.query(Customer).filter_by(customer_id=customer_id).first()
def get_with_high_value_invoices(self, min_amount=100):
return (
self.session.query(Customer)
.join(Customer.invoices)
.filter(Invoice.total >= min_amount)
.distinct()
.all()
)
def update_email(self, customer_id, new_email):
customer = self.get_by_id(customer_id)
if customer:
customer.email = new_email
return customer
# Unit of Work with SQLAlchemy session
class UnitOfWork:
def __init__(self):
self.session_factory = Session
def __enter__(self):
self.session = self.session_factory()
self.customers = CustomerRepository(self.session)
return self
def __exit__(self, exc_type, exc_val, exc_tb):
try:
if exc_type is not None:
self.rollback()
else:
self.commit()
finally:
self.session.close()
def commit(self):
self.session.commit()
def rollback(self):
self.session.rollback()
# Application code
with UnitOfWork() as uow:
high_value_customers = uow.customers.get_with_high_value_invoices(500)
for customer in high_value_customers:
print(f"VIP Customer: {customer.first_name} {customer.last_name}")
This layered approach gives you the best of all worlds: domain-focused code, clean separation of concerns, and the power of SQLAlchemy's ORM to handle the complex object-relational mapping.
But whichever pattern you pull out, always retain understanding of the layers beneath. Ignorance is NOT bliss and even the best ORM can't optimize what you don't comprehend.
Deepdives
The following are standalone sections. I recommend reading them after reviewing the main content so you understand how the pieces fit and the motivations behind them.
The Repository: From Raw SQL to Semantics
The Repository pattern transforms database interactions from imperative SQL statements to semantic method calls. For developer collaboration, repositories create a clear contract between data access and business logic. This separation is super useful as applications grow, enabling independent evolution of both layers.
By implementing a repo, you get some great engineering benefits such as:
- Domain-Database Separation - Keeps SQL out of your business logic
- Testing Simplification - Enables mocking the database for unit tests
- Implementation Flexibility - Allows changing database technology without affecting business code
- Centralized Query Logic - Prevents SQL duplication across the codebase
Here is a codestub to illustrate:
class CustomerRepository:
def __init__(self, connection):
self.conn = connection
def get_by_id(self, customer_id: int) -> Optional[Dict[str, Any]]:
cursor = self.conn.cursor()
cursor.execute("SELECT * FROM customers WHERE CustomerId = ?", (customer_id,))
row = cursor.fetchone()
if not row:
return None
return {"CustomerId": row[0], "Email": row[1]}
def update_email(self, customer_id: int, new_email: str) -> bool:
cursor = self.conn.cursor()
cursor.execute(
"UPDATE customers SET Email = ? WHERE CustomerId = ?",
(new_email, customer_id)
)
return cursor.rowcount > 0
When combined with the Unit of Work pattern, repositories gain transaction coordination without tight coupling to transaction management code. When combined with ORMs, repositories provide a clean interface between business logic and database operations.
Unit of Work: Transaction Best Practices in Reusable form
The Unit of Work pattern wraps database transaction best practices into a consistent, reusable form. It acts as a transaction coordinator that maintains clear boundaries around related operations, ensuring they succeed or fail as a complete unit.
Its responsibilities are:
- Transaction boundaries - Beginning and ending transactions
- Connection lifecycle - Obtaining and releasing connections
- Repository coordination - Providing repositories with a shared connection
- Error handling - Automatic rollback on exceptions
I like to also think of this as a "shopping cart" for database changes - you add, modify, or delete items, and then either check out (commit) or abandon the cart (rollback). By standardizing this pattern in your codebase, you eliminate duplicated transaction handling logic and ensure consistent resource management practices in every database interaction. Put another way, with the UoW, multiple operations become grouped into one atomic transaction.
In python, this is done by using the context manager protocol (__enter__ and __exit__), the UoW creates a clean, readable syntax for transaction management:
class CustomerUnitOfWork:
def __enter__(self):
# Initialize connection when entering context
self.conn = sqlite3.connect(self.db_path)
self.conn.isolation_level = 'DEFERRED'
# Create repositories that share this connection
self.customer_repository = CustomerRepository(self.conn)
return self
def __exit__(self, exc_type, exc_val, exc_tb):
# Commit or rollback based on whether an exception occurred
try:
if exc_type is not None:
self.rollback()
else:
self.commit()
finally:
self.conn.close()
# Implementation Example
with CustomerUnitOfWork('chinook.db') as uow:
customer = uow.customer_repository.get_by_id(1)
if customer:
uow.customer_repository.update_email(1, 'updated@example.com')
# No explicit commit needed - happens automatically if no exceptions
ORMs: Key Concepts and Their Implementation
Engine: The Database Connection Factory
The create_engine() function produces the central component in SQLAlchemy's architecture - the Engine. The Engine is designed to be a long-lived, application-wide resource. It's thread-safe and typically created once at application startup.
When you create an engine, you're setting up a connection management system that:
- Creates a connection pool (reusable connections)
- Manages connection lifecycle and health
- Manages dialect-specific SQL generation
- Provides thread-safe database access
Key Properties
url- Connection string used to establish connectionsdialect- Database-specific implementation (PostgreSQL, MySQL, SQLite)pool- The connection pool managerdriver- The DBAPI implementation being used
Key Methods
connect()- Returns a Connection object from the poolexecute()- Convenience method to execute SQL without managing connectionsdispose()- Closes all connections and releases resourcesbegin()- Returns a Connection with a transaction contexthas_table()- Checks if a table exists in the database
Declarative Base: The Model Foundation
The declarative_base() function creates a base class that serves as the foundation for all your ORM models. Think of it as the parent class that brings SQLAlchemy's mapping machinery to your domain classes.
When you create models that inherit from this base:
class Customer(Base):
__tablename__ = 'customers'
customer_id = Column(Integer, primary_key=True)
You're doing several things at once:
- Registering the class with SQLAlchemy's mapping system
- Enabling metadata tracking for schema generation
- Adding ORM functionality like relationship management
- Creating a bridge between your Python classes and database tables
The Base class maintains a catalog (metadata) of all mapped classes and their corresponding tables, which is essential for:
- Schema generation and validation
- Foreign key relationship resolution
- Session registration of instances
- Query construction and execution
Without this foundation, your models would be just regular Python classes with no connection to the database layer.
SessionMaker: The Session Factory
The sessionmaker is a configurable factory that produces Session objects with consistent settings.
- Maintains consistent settings across all sessions
- Typically created once during application startup
- Not thread-safe - meant to create sessions, not be used directly
Key Properties
kw- Dictionary of configuration parametersclass_- The Session class being created
Key Methods
__call__()- Creates a new Session instanceconfigure()- Updates configuration parametersidentity_map()- Access to identity map configuration
Sessions created by the same sessionmaker share consistent behavior:
# Create two sessions with identical configuration
session1 = Session()
session2 = Session()
# Both have the same autoflush, expire_on_commit settings
assert session1.autoflush == session2.autoflush
When your application needs to change database connections (like for testing):
# Reconfigure the session factory to use a different engine
Session.configure(bind=test_engine)
This architecture gives you thread-safe database access with consistent configuration across your application.
The ORM engine is like a factory for your database connectivity - it establishes and maintains the network connections your application needs to communicate with the database. Conceptually, think of it as a specialized factory that produces database connections on demand while efficiently managing their lifecycle.
In Code
Here's how these components work together in SQLAlchemy:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# Engine - thread-safe, application-wide resource
engine = create_engine(
'postgresql://user:password@localhost/dbname',
pool_size=10, # Maintain 10 connections
max_overflow=20, # Allow 20 more when busy
pool_timeout=30, # Wait 30 sec for connection
pool_recycle=3600 # Recycle connections after 1 hour
)
# Session factory - configured template for sessions
Session = sessionmaker(
bind=engine,
autocommit=False, # Transactions not auto-committed
autoflush=True, # Changes flushed before queries
expire_on_commit=True # Refresh objects after commit
)
# Base class for declarative models
Base = declarative_base()
ORMs: A few useful patterns
Query Objects: Encapsulate complex query logic in dedicated classes
- Benefit: Centralizes query logic, making it reusable and testable
- When to use: For complex queries that appear in multiple places
class CustomerQueries:
def __init__(self, session):
self.session = session
def high_value_customers(self, min_purchase=1000):
return (
self.session.query(Customer)
.join(Customer.orders)
.group_by(Customer.id)
.having(func.sum(Order.amount) > min_purchase)
.all()
)
Lazy Loading vs. Eager Loading: Control when related data is loaded
- Benefit: Eliminates N+1 query problems, optimizes performance
- When to use: Eager loading for predictable access patterns, lazy for sporadic access
# Lazy loading (default) - loads related objects on access
customer = session.query(Customer).get(1)
# SQL query happens here, when the relationship is accessed
orders = customer.orders
# Eager loading - loads related objects immediately
customer = (
session.query(Customer)
.options(joinedload(Customer.orders))
.get(1)
)
# No additional SQL query needed
orders = customer.orders
Bulk Operations: Optimize for mass updates or inserts
- Benefit: Dramatically improves performance for large datasets
- When to use: When operating on hundreds or thousands of records
# Instead of:
for user in users:
user.is_active = False
session.add(user)
# Use bulk update:
session.query(User).filter(User.id.in_([u.id for u in users])).update(
{"is_active": False}, synchronize_session=False
)
Event Listeners: React to model lifecycle events
- Benefit: Encapsulates cross-cutting concerns like auditing or data transformation
- When to use: For consistent behavior that should apply automatically
from sqlalchemy import event
@event.listens_for(User, 'before_insert')
def hash_password(mapper, connection, target):
if target.password:
target.password = hash_password(target.password)