Reflections from Our Beta Launch
TLDR
We just shipped the beta version of the app we're working on. The domain itself was wickedly complex with lots of interdependencies in state management AND a graph-based data structure.
Hindsight is 20/20 and these retroactive principles are a way for me to think back and internalize some hard-earned lessons.
... Let's get to it!
Domain Modeling Lessons
Proof-of-Concepts != Good Design
The early proof of concept model I built is virtually non-existent in the present-day codebase. I would argue that even building it was a waste of time.
When faced with complex chemical processes with a boat-load of equipments and material flows, starting with code immediately leads to a tangled mess.
Instead, mapping out entities, value objects, and their relationships first provides a solid foundation. This transforms the initial phase into a design exercise rather than a coding one. This prevents the all-too-common situation where early implementation decisions constrain future design choices.
# Bad approach: Diving straight into implementation
class ChemicalPlant:
def __init__(self):
self.equipments = []
self.streams = []
# Immediately jumping to implementation details
def calculate_emissions(self):
# Ad-hoc calculations without domain model backing
pass
# Good approach: Start with domain modeling
# domain_model.py - Clear model before implementation
class Equipment(Entity):
"""Base class for all equipment in a chemical plant."""
id: UUID
name: str
type: EquipmentType
class MaterialStream(Entity):
"""Represents flow of materials between equipment."""
id: UUID
source: UUID # Equipment UUID
target: UUID # Equipment UUID
composition: Composition
Explicit, Batched Validation > Implicit, Nested Validation
Implementing explicit, batched validation at the aggregate level significantly improves debugging and operational observability. This approach aligns perfectly with batch data processing needs in REST-API driven applications where data often arrives in batches.
Rather than scattering validation logic throughout individual properties, centralizing validation in aggregate roots helps identify related issues and provides comprehensive error reporting. This is especially valuable when dealing with complex interdependent calculations like mass and energy balances.
# Bad approach: Scattered validation
class ChemicalReactor:
def set_temperature(self, temp):
if temp 500:
raise ValueError("Temperature out of range")
def set_pressure(self, pressure):
if pressure 100:
raise ValueError("Pressure out of range")
# Validation scattered throughout methods
# Good approach: Batched validation
class ChemicalReactor(AggregateRoot):
temperature: float
pressure: float
catalyst_load: float
def validate(self) -> list[ValidationError]:
errors = []
if self.temperature 500:
errors.append(ValidationError("temperature", "out of range"))
if self.pressure 100:
errors.append(ValidationError("pressure", "out of range"))
if self.catalyst_load 300 and self.pressure > 80:
errors.append(ValidationError("operation", "unsafe temperature/pressure combination"))
return errors
Ignorance is Bliss: Decouple Between Object Hierarchies
Minimizing parent-child dependencies has been essential for our system's scalability. Components should operate independently, with parent context logic belonging firmly at the parent layer. When children become aware of their parents, you create complex dependency chains that break encapsulation and make testing difficult.
This principle proved critical when modeling chemical plants where equipment hierarchies exist (e.g., a distillation column containing compounds, mixed states, etc). Keeping child components unaware of their parent context allows for easier reuse and testing in isolation.
# Bad approach: Child depends on parent
class DistillationTray:
def __init__(self, column, position):
self.column = column # Reference to parent
self.position = position
def calculate_efficiency(self):
# Directly accesses parent properties creating tight coupling
feed_composition = self.column.feed_composition
reboiler_duty = self.column.reboiler.duty
# Calculation using parent properties
# Good approach: Parent coordinates child operations
class DistillationTray:
def __init__(self, position, tray_type, diameter):
self.position = position
self.tray_type = tray_type
self.diameter = diameter
def calculate_efficiency(self, vapor_flow, liquid_flow, feed_composition):
# Calculate using parameters passed from parent
# No direct dependency on parent
class DistillationColumn:
def __init__(self, trays, reboiler, condenser):
self.trays = trays
self.reboiler = reboiler
self.condenser = condenser
def calculate_tray_efficiencies(self):
# Parent coordinates operations on children
for tray in self.trays:
# Parent passes relevant context to child
efficiency = tray.calculate_efficiency(
self.vapor_flow_at(tray.position),
self.liquid_flow_at(tray.position),
self.composition_at(tray.position)
)
Entity and Value Object Design
UUIDs for Entities
Using UUIDs for Entity identification ensures global uniqueness, which is especially crucial in distributed systems. In our graph-based model of chemical plants, being able to reference any entity globally without ambiguity was essential for operations that span multiple subsystems.
UUIDs eliminate coordination problems when different parts of the system need to create new entities and provide guaranteed uniqueness across system boundaries - a necessity when integrating with external data sources like equipment databases or IoT devices.
# Bad approach: Numeric or string IDs that might conflict
class Pump:
def __init__(self, id_number):
self.id = id_number # Potential for conflicts
# Good approach: UUIDs for global uniqueness
import uuid
class Pump(Entity):
id: uuid.UUID = field(default_factory=uuid.uuid4)
name: str
capacity: float
# Now we can reference this pump globally without ambiguity
Enums for Value Objects
Using Enums as clear, type-safe labels to identify and access specific Value Objects within Entities enhances domain clarity and code readability. This provides compile-time safety and communicates domain concepts effectively.
When modeling complex entities that might have multiple connection points, material states, or operational modes, enums provide a structured way to access these without resorting to magic strings or numbers.
Also, use auto and unique.
# Bad approach: String literals for types
def get_connection(self, connection_type):
if connection_type == "inlet":
return self.inlet
elif connection_type == "outlet":
return self.outlet
# Prone to typos, no IDE completion
# Good approach: Enums for type safety
from enum import Enum, auto
class ConnectionType(Enum):
INLET = auto()
OUTLET = auto()
SAMPLING = auto()
DRAIN = auto()
class Reactor(Entity):
# ...
def get_connection(self, connection_type: ConnectionType):
return self.connections[connection_type]
# Usage
reactor.get_connection(ConnectionType.INLET) # Clear, type-safe
Head-ache-free Value Objects
Enforcing immutability on Value Objects prevents side effects and ensures predictable state.
Value Objects are defined by their attributes, not by identity, making them immutable and replaceable. This approach drastically reduces bugs related to unexpected state changes.
In chemical engineering, many concepts like material compositions, temperature points, and pressure settings are naturally Value Objects – they're defined by their values, not by identity, and should be immutable.
# Bad approach: Mutable value objects
class Composition:
def __init__(self, components):
self.components = components # Dict of component name to fraction
def add_component(self, name, fraction):
self.components[name] = fraction # Mutable, can cause side effects
# Good approach: Immutable value objects
from dataclasses import dataclass, field
from typing import Dict
@dataclass(frozen=True)
class Composition:
components: Dict[str, float]
def with_component(self, name, fraction):
# Returns a new instance instead of modifying
new_components = dict(self.components)
new_components[name] = fraction
return Composition(new_components)
def __post_init__(self):
# Validate that fractions sum to 1.0
if abs(sum(self.components.values()) - 1.0) > 1e-6:
raise ValueError("Component fractions must sum to 1.0")
Pydantic for Free Serialization
Using Pydantic as the base for all domain model classes saves tremendous time with serialization, type safety, and validation. This is especially valuable in data-intensive domains where proper data validation is critical.
Pydantic's automatic JSON serialization and deserialization, combined with its validation capabilities, eliminates boilerplate code while ensuring data integrity. This became crucial when our system needed to exchange data with frontend visualization components and external APIs.
# Bad approach: Manual serialization/deserialization
class Measurement:
def __init__(self, timestamp, value, unit):
self.timestamp = timestamp
self.value = value
self.unit = unit
def to_dict(self):
return {
"timestamp": self.timestamp.isoformat(),
"value": float(self.value),
"unit": self.unit,
}
@classmethod
def from_dict(cls, data):
return cls(
datetime.fromisoformat(data["timestamp"]),
float(data["value"]),
data["unit"]
)
# Good approach: Pydantic for automatic serialization
from pydantic import BaseModel, Field
from datetime import datetime
class Measurement(BaseModel):
timestamp: datetime
value: float = Field(gt=0) # Must be positive
unit: str = Field(regex=r"^[A-Za-z]+$") # Unit validation
# Automatic serialization/deserialization
# Built-in validation
# JSON schema generation
# And much more for free!
Interface and Class Design
Interfaces (protocol) for Contracts
Defining interfaces using Python's protocol system establishes clear contracts and promotes polymorphism. This approach allows different implementations to satisfy the same contract without inheritance, which is especially valuable in a complex domain.
# Bad approach: Implicit interfaces
class EmissionCalculator:
def calculate(self, equipment):
# Abstract method without enforcement
pass
# Good approach: Explicit protocols
from typing import Protocol, runtime_checkable
@runtime_checkable
class EmissionCalculator(Protocol):
"""Contract for any emission calculator"""
def calculate(self, equipment: Equipment) -> float:
"""Calculate emissions in kg CO2e"""
...
# Implementations must satisfy the protocol
class DirectEmissionCalculator:
def calculate(self, equipment: Equipment) -> float:
# Implementation for direct emissions
return equipment.fuel_consumption * equipment.emission_factor
# Usage with type checking
def report_emissions(calculator: EmissionCalculator, equipment: Equipment):
emissions = calculator.calculate(equipment)
# Rest of the function
ABCs (abc) for Categorization
Employing Abstract Base Classes (ABCs) for structuring and categorizing types enables code reuse while enforcing implementation contracts. This works well for categorizing entities and organizing hierarchies of domain objects.
In our chemical plant model, we have diverse equipment types that share common properties but have specialized behaviors. ABCs helped create meaningful categorizations while ensuring implementations provided required functionality.
# Bad approach: Duplicated code across similar classes
class Pump:
def __init__(self, power_rating):
self.power_rating = power_rating
def calculate_energy(self, hours):
return self.power_rating * hours
class Compressor:
def __init__(self, power_rating):
self.power_rating = power_rating
def calculate_energy(self, hours):
return self.power_rating * hours
# Good approach: ABC for shared behavior
from abc import ABC, abstractmethod
class RotatingEquipment(ABC):
def __init__(self, power_rating):
self.power_rating = power_rating
def calculate_energy(self, hours):
"""Shared implementation for energy calculation"""
return self.power_rating * hours
@abstractmethod
def calculate_efficiency(self):
"""Each subclass must implement efficiency calculation"""
pass
class Pump(RotatingEquipment):
def calculate_efficiency(self):
# Pump-specific implementation
class Compressor(RotatingEquipment):
def calculate_efficiency(self):
# Compressor-specific implementation
Data Structures & Class Patterns
Flat Entities with Graph References
A key insight from my implementation was that entities should live in flat data structures and then be referenced for graphs or other complex structures, rather than living solely within those structures. This approach provides flexibility, reusability, and better persistence strategies.
When modeling chemical plants as graphs, having equipment and streams as standalone entities that are referenced in the graph structure (rather than nested within it) allows for more flexible querying, better persistence options, and easier refactoring.
# Bad approach: Entities nested in graph structure
class ChemicalPlant:
def __init__(self):
self.equipment_graph = {
# Equipment nested directly in graph
"reactor1": {
"type": "Reactor",
"volume": 2000,
"connections": ["pump1", "heat_exchanger1"]
},
"pump1": {
"type": "Pump",
"power": 75,
"connections": ["reactor1", "tank1"]
}
# Equipment only exists within this graph
}
# Good approach: Flat entities with graph references
class ChemicalPlant:
def __init__(self, equipment_registry, connection_graph):
# Registry contains all equipment as standalone entities
self.equipment_registry = equipment_registry
# Graph only contains references to equipment
self.connection_graph = connection_graph
# Usage
equipment_registry = {
UUID('abc-123'): Reactor(id=UUID('abc-123'), volume=2000),
UUID('def-456'): Pump(id=UUID('def-456'), power=75)
}
connection_graph = {
UUID('abc-123'): [UUID('def-456')], # reactor → pump
UUID('def-456'): [UUID('abc-123')] # pump → reactor
}
plant = ChemicalPlant(equipment_registry, connection_graph)
# Benefits:
# - Equipment can exist independently of any specific graph
# - Same equipment can be referenced in multiple graphs
# - Persistence can be optimized for entities and relationships separately
# - Queries can be performed on flat collections efficiently
Class Default Initialization: DI > Class Var
For our code, we used class variables to define various class defaults. While this enable really quick prototyping in the early stage, it led to several issues as the system scaled:
- Runtime Initialization Complexity: Class variables are evaluated at import time, creating implicit dependencies that can lead to circular imports and initialization order conflicts1. This becomes particularly problematic in large chemical plant models where equipment classes may reference each other.
- Reduced Testability: Hard-coded class variables make it difficult to isolate test cases, as modifications to defaults persist across test runs. This violates the principle of test independence crucial for maintaining complex simulation systems.
- Configuration Rigidity: The current structure offers no clear path for environment-specific configuration or dynamic adjustment of defaults based on operational context – a critical requirement for chemical plants operating under different regulatory regimes.
Instead, have defaults in a dictionary or other simple data structure that is explicitly passed to the class as an input argument. This bakes in the option of migrating to yamls or client-set defaults.
# Current Stub
class ConversionReactor(ENTBaseEquipment):
CONTVAR_DEFAULTS = {
VOContinuousVariable(
ContVarSpecEnum.PressureDrop_ConversionReactor, 0, (0, 10_000.0)
),
...
}
DISCRETESET_DEFAULTS = {
VODiscreteVariable(
variable_enum=DiscreteSetSpecEnum.CalculationType,
init_value=DiscreteItemSpecEnum.RCT_Conversion_Adiabatic,
bounds={
DiscreteItemSpecEnum.RCT_Conversion_Adiabatic,
DiscreteItemSpecEnum.RCT_Conversion_Isothermic,
DiscreteItemSpecEnum.RCT_Conversion_DefineOutletTemp,
},
),
}
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._reactionset: Set[ConversionReaction] = set()
def __deepcopy__(self, memo):
# ConversionReactor
new_obj = type(self)(self.label)
memo[id(self)] = new_obj
# Copy base attributes
for k, v in self.__dict__.items():
if k != "_reactionset":
setattr(new_obj, k, copy.deepcopy(v, memo))
# Use existing methods to establish relationships
for reaction in self._reactionset:
new_reaction = copy.deepcopy(reaction, memo)
new_obj.add_reaction(new_reaction)
return new_obj
@property
def reactionset(self) -> Set[ConversionReaction]:
return self._reactionset
...
# POSTIVIE EXAMPLE
class ReactorDefaults(BaseModel): # Can be class or simple dict
"""Injectable configuration for conversion reactors"""
continuous_vars: Dict[str, tuple] = Field(
default_factory=lambda: {
"pressure_drop": (0, 0, 10000.0),
"temperature_diff": (0, 0, 100000000),
"heat_load": (0, 0, 100000000),
"outlet_temp": (1, 0, 100000000)
},
description="Continuous variable specifications"
)
discrete_options: Dict[str, Set[str]] = Field(
default_factory=lambda: {
"calculation_type": {
"adiabatic",
"isothermic",
"outlet_temp_defined"
}
},
description="Available discrete calculation modes"
)
var_collections: list = Field(
default_factory=lambda: [
"VarCollectionDiscreteSet",
"VarCollectionContinuous"
]
)
class ConversionReactor(ENTBaseEquipment):
def __init__(
self,
label: str,
config: ReactorDefaults = ReactorDefaults(),
reaction_set: Optional[Set[ConversionReaction]] = None
):
super().__init__(label)
self.config = config
self._reaction_set = reaction_set or set()
# Initialize variables from config
self._init_continuous_vars()
self._init_discrete_vars()
def _init_continuous_vars(self):
"""Create continuous variables from configuration"""
for var_name, (init, min_val, max_val) in self.config.continuous_vars.items():
self._add_continuous_variable(
ContVarSpecEnum[var_name],
init,
(min_val, max_val)
)
def _init_discrete_vars(self):
"""Initialize discrete calculation modes"""
for var_name, options in self.config.discrete_options.items():
enum_type = DiscreteSetSpecEnum[var_name]
self._add_discrete_variable(
enum_type,
DiscreteItemSpecEnum[next(iter(options))], # Default first option
{DiscreteItemSpecEnum[opt] for opt in options}
)
Enums values should be simple and arbitrary
Our enums currently serve 2 functions: type-safety… and configuration lookups. This means that the enum value is mapped to a complex object.
Where this becomes troublesome is during serialization/deserialization. This led to some limitations:
- Serialization Complexity: Complex Enum values require custom serialization logic that becomes brittle across schema versions
- Domain Model Pollution: Business logic becomes entangled with presentation-layer concerns like labels and units
- Extension Barriers: Adding new parameter types requires modifying Enum definitions rather than external configuration
If this was refactored, it would still be necessary to have configuration lookups, but the mapping between enum to config should happen at a layer above the enum, like in a simple dictionary or similar.
# Existing
@unique
class ContVarSpecEnum(BaseSpecEnum):
"""
Policy for defining different parameter types with associated default values and behaviors.
Each member of the enum holds a `Specification` instance containing relevant information
for a particular parameter.
"""
ReactionStoich = _ContVarSpecification(
label="reaction stoichiometry",
unit_of_measurement="Ratio",
parameter_category=VariableCategoryEnum.NONE,
)
TemperatureDifference = _ContVarSpecification(
label="temperature difference",
unit_of_measurement="K",
parameter_category=VariableCategoryEnum.SETPOINT,
)
Temperature = _ContVarSpecification(
label="temperature",
unit_of_measurement="K",
parameter_category=VariableCategoryEnum.SETPOINT,
)
# POSTIVIE EXAMPLE
@unique
class ContVarSpecEnum(str, Enum):
"""Simple enum for variable type identification"""
PRESSURE_DROP = "pressure_drop"
TEMPERATURE_DIFF = "temperature_difference"
HEAT_LOAD = "heat_load"
OUTLET_TEMP = "outlet_temperature"
class VariableSpecification(BaseModel):
"""External configuration store"""
label: str
unit: str
category: str
display_precision: int = 2
persistence_key: Optional[str] = None
# Configuration registry loaded from external source
VAR_SPEC_REGISTRY: Dict[ContVarSpecEnum, VariableSpecification] = {
ContVarSpecEnum.PRESSURE_DROP: VariableSpecification(
label="Pressure Drop",
unit="kPa",
category="hydrodynamics"
),
...
}
class ContinuousVariable(BaseModel):
"""Domain model for process variables"""
spec_type: ContVarSpecEnum
current_value: float
min_value: float
max_value: float
@property
def metadata(self) -> VariableSpecification:
"""Access configuration through registry"""
return VAR_SPEC_REGISTRY[self.spec_type]
# Usage example
temp_var = ContinuousVariable(
spec_type=ContVarSpecEnum.TEMPERATURE_DIFF,
current_value=150,
min_value=0,
max_value=1000
)
print(temp_var.metadata.unit) # Outputs '°C'
Service Layer = Infrastructure * Core Modules
Methods = Business Use Cases
Service class methods should directly implement specific business use cases for clear code-to-business alignment.
In a mock energy optimization application, aligning service methods with specific business operations such as "calculate monthly emissions report" or "optimize reactor temperature profile" made the codebase self-documenting and improved collaboration with domain experts.
# Bad approach: Technical/implementation-focused methods
class PlantService:
def process_data(self, data):
# Generic, technical method name
def run_algorithm(self, parameters):
# Doesn't communicate business intent
# Good approach: Business-focused methods
class EmissionsService:
def __init__(self, emission_calculator, data_repository):
self.emission_calculator = emission_calculator
self.data_repository = data_repository
def generate_monthly_emissions_report(self, plant_id, month, year):
"""Generate a monthly emissions report for regulatory compliance"""
plant = self.data_repository.get_plant(plant_id)
operational_data = self.data_repository.get_operational_data(plant_id, month, year)
return self._calculate_emissions(plant, operational_data)
def optimize_production_schedule_for_minimal_emissions(self, plant_id, production_targets):
"""Find optimal production schedule to minimize carbon emissions while meeting targets"""
# Implementation of this specific business use case
Dependency Injection for Infrastructure Flexibility
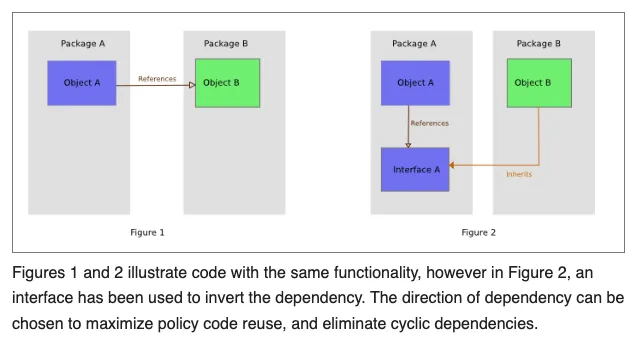
The service layer acts as the coordinator between domain logic and infrastructure, allowing a single codebase to adapt to multiple environments. By injecting repositories, loggers, calculators, etc., you insulate business logic from technical details and can pivot among in-memory, local, or cloud providers with minimal disruption.
A hard lesson learnt when designing the service layer is to inject all infrastructure dependencies rather than instantiating them directly within the service.... or worse... in the core domain.
This follows the dependency inversion principle, allowing high-level business logic to remain independent of low-level infrastructure details
("High-level modules should not import anything from low-level modules. Both should depend on abstractions (e.g., interfaces))
Implementing a Service Superclass
The pattern described above naturally leads to implementation as a service superclass. This approach aligns with the concept of "Superclass Service Providers" where the superclass provides invariant infrastructure services to subclasses through well-defined extension points.
The things that should be configurable:
- repository (aka persistence model)
- runner (for distributed / local)
- logging (console / to text file / to dashboard)
class BaseService:
"""Base service providing infrastructure configuration."""
def __init__(self,
repository=None,
logger=None,
metrics_collector=None,
tracing_service=None,
circuit_breaker_factory=None,
retry_policy=None,
cache_provider=None,
rate_limiter=None):
# Set up infrastructure with sensible defaults
self.repository = repository or InMemoryRepository()
self.logger = logger or ConsoleLogger()
self.metrics = metrics_collector or NoopMetricsCollector()
self.tracer = tracing_service or NoopTracer()
self.circuit_breaker = circuit_breaker_factory or NoopCircuitBreaker()
self.retry_policy = retry_policy or NoRetryPolicy()
self.cache = cache_provider or NoopCache()
self.rate_limiter = rate_limiter or NoopRateLimiter()
...
def execute_with_resilience(self, operation, *args, **kwargs):
"""Template method for executing operations with fault tolerance."""
try:
with self.tracer.start_span(operation.__name__):
with self.circuit_breaker:
start_time = time.time()
result = self.retry_policy.execute(operation, *args, **kwargs)
duration = time.time() - start_time
self.metrics.record_duration(operation.__name__, duration)
return result
except Exception as e:
self.logger.error(f"Error executing {operation.__name__}: {e}")
raise
# Example concrete service
class EmissionService(BaseService):
def __init__(self, calculator, notification_service=None, **kwargs):
super().__init__(**kwargs) # Pass infrastructure to base class
self.calculator = calculator
self.notification_service = notification_service
def calculate_emissions(self, plant_id):
# Now we can use the base class's resilience features
plant = self.execute_with_resilience(
self.repository.get_plant, plant_id)
# Cached calculation for common requests
cache_key = f"emissions:{plant_id}"
cached = self.cache.get(cache_key)
if cached:
return cached
emissions = self.calculator.calculate(plant)
self.logger.info(f"Calculated emissions for plant {plant_id}: {emissions}")
# Store in cache for future requests
self.cache.set(cache_key, emissions, ttl=3600)
if emissions > REGULATORY_THRESHOLD and self.notification_service:
self.execute_with_resilience(
self.notification_service.send_alert,
f"Plant {plant_id} exceeds emission threshold")
return emissions
Environment-Specific Configuration
With the above... this allows the same business logic to run across different environments with appropriate infrastructure for each context.
| Infrastructure Component | Development | Production |
|---|---|---|
| Repository | In-Memory Dict | Cloud SQL |
| Logger | Console | OpenTelemetry |
| Circuit Breaker | None | 5 failures/30s |
Composition Root Configuration
A key consideration when implementing dependency injection is where to configure these dependencies.
"You should always configure the DI container at a single place, as near to the application entry point as possible. This is called the composition root."
In plain english, put this in build_app. This creates a single point of control for all infrastructure configuration, making it easier to manage environment-specific settings and dependencies.
# In application bootstrap code
def configure_services(config):
"""Configure all services based on environment configuration."""
# Set up common infrastructure
if config.environment == "development":
repository = InMemoryRepository()
logger = ConsoleLogger(level="DEBUG")
# Other dev infrastructure...
elif config.environment == "production":
repository = PostgresRepository(config.db_connection_string)
logger = CloudLogger(level="INFO")
# Other production infrastructure...
# Configure and register services
emission_service = EmissionService(
calculator=EmissionCalculatorFactory.create(config),
repository=repository,
logger=logger,
# Other infrastructure dependencies...
)
# Register in service registry for dependency injection
service_registry.register("emission_service", emission_service)
And ...✨Tada✨ we live to code another day
At the end of the day, the beta shipped despite all the hard lessons learnt (read: mistakes made and midnight debug session)
We're going to see how to slowly incorporate some of the above as we chug along. Its painful to accept thatcode is... always a work in progress.
Navel gazing aside, here are the TLDRs
- Model First, Code Later - A day spent whiteboarding domain relationships saves a week of refactoring
- Infrastructure as Plugin - DI enables evolving from in-memory mocks to cloud-native without logic changes
- Validation is Observability - Batched validation errors become monitoring metrics in production
- There will be bugs - So, build in a manner that enables high-velocity testing & debugging. Decoupling infrastructure and core modules is a key step in that.
I'd love to hear how you have tackled similar challenges. What patterns have worked for you in complex domains? Reach out via email or other ways!