Scaling Platforms: Managing Complexity with Interfaces & Adapters
TLDR
Following the beta launch of our platform, I had two big challenges to solve:
- Complexifying Deployment Scenarios - how to cater to increasingly customized demands of enterprise deployments?
- Complexifying Infrastructural Combinations - how to elegantly manage the increasing permutations of feature-to-simulation/prediction engine-to-analytical_method as we integrated more simulators and ML libraries, each with their own compute strategies and preferred analytical methods?
Continuing development-as-is with our base system architecture would quickly accumulate technical debt at an increasing rate of interest. The decision was made to refactor in step-wise manner and adopt the ports-and-adaptor pattern. The larger vision was to lay the groundwork to transition to an events-driven architecture, which is more suited to ML platforms with long running processes and monitoring.
Ok, Let's dive into it.
The Problem: Infrastructure Dependencies Limiting System Flexibility
For our application, we faced several architectural challenges that hindered scalability and maintainability:
- CICD Limitations – Unable to execute automated CICD pipelines due to tight coupling between tests and infrastructure.
- Diagnostic Complexity - Debugging required coordinated sessions across engineering teams due to mixed architectural layers.
- Expanding Use Case Variations - Our system needed to handle increasingly diverse model types, data sources, and deployment configurations—particularly challenging with surrogate models requiring custom training and evaluation pipelines.
- Multi-Environment Deployment - The need to deploy identical business logic across our cloud, client infrastructure, and local development environments while maintaining a single codebase.
If you've been an engineer dealing with any of the above, then you'll agree that it really turns the work into a grind. At the end of the day, I think it feels so much better to be working in a system that feels well-engineered™.
This is a short post of how the Ports and Adapters pattern was adapted to solve these challenges, especially in applications dealing with ML and analytics.
Core Architectural Principles
The Fundamental Rule: Domain Independence
The cornerstone principle of Ports and Adapters architecture is straightforward and powerful:
"Internal modules should not be aware of outer modules."
This creates an outward dependency flow that shields core logic from external implementation details like infrastructure. Essentially, its dependency topology: is a directed acyclic graph (DAG) that prevents circular references.dependencies
Rather than the traditional "hexagon" metaphor, I find it more intuitive to visualize this as n-sided polygon model, where:
- The core modules exist in its own space, defined purely by its invariants
- Each "dimension" represents a family of external concerns abstracted through interface contracts
- Adapters implement transformations between the domain's abstract requirements and concrete infrastructure capabilities
For our ML platform, we categorized these external concerns into two practical groups:
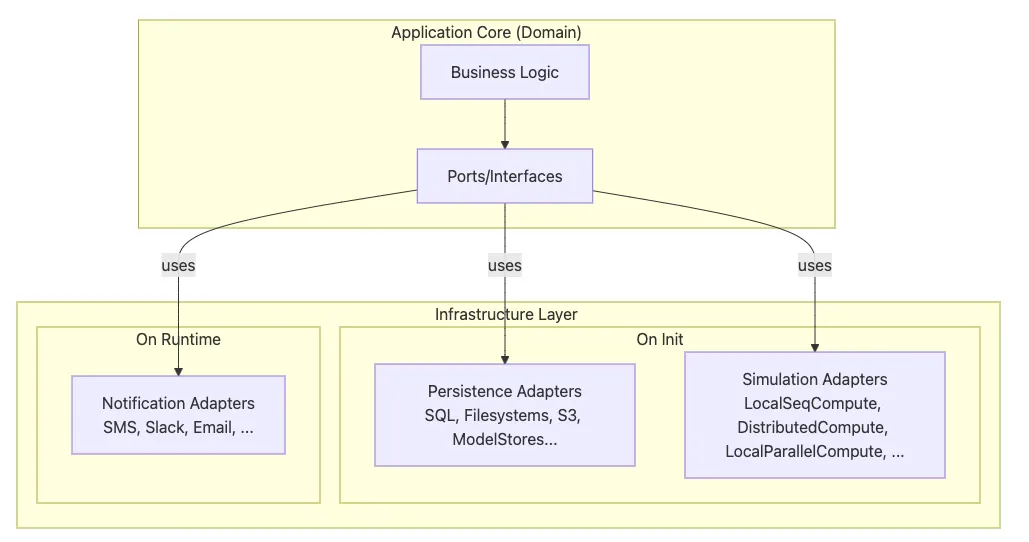
Initialization-Bound Interfaces These are resolved when the application starts up, typically varying by deployment environment:
- Simulation Engines (distributed Spark clusters in production, local execution in development)
- Persistence Adapters (Aurora PostgreSQL in production, SQLite in testing)
- External APIs (live endpoints in production, stubbed responses in testing)
- Logging Infrastructure (Cloudwatch in production, console in development)
Request-Bound Interfaces These are resolved during request handling, often determined by request parameters:
- Notification Services (Slack, email, or SMS based on user preferences)
- Licensing Services (enterprise vs. standard feature sets)
- Security Contexts (permission-based resource access)
Component Architecture: Enforcing Bounded Contexts Through Layering
The effectiveness of Ports and Adapters relies on discipline in maintaining clear layer boundaries and communication patterns. For our ML platform, we established a strict three-layer architecture that created clear ownership boundaries and drastically simplified testing strategies:
Domain Layer: Pure Logic I like to think of this as stations in a kitchen. Each is an island dedicated to a specific purpose: hot, grills, etc.This inner layer contains stateless, deterministic components with zero infrastructure dependencies:
- Domain Models & Rules: Immutable entity definitions and business rule validations (implemented with Pydantic for type-safety and serialization)
- Pure Functions with Declarative Configurations: Stateless transformation functions operating on well-defined dataframe schemas (see deepdive). Essentially, mathematical machines without any side-effects or mutuations that can be composed together.
- Port Interfaces: Abstract contracts exposing core behaviour in a user-friendly manner.
I adopted a key design principle: configuration is declarative, computation is functional and stateless. i.e For Pure Functions, attributes serve only as configuration parameters, while all data transformations occur through pure functions with explicit inputs and outputs—facilitating composition and testability.
Application Layer: Use Case Orchestration This middleware layer coordinates interactions between domain logic and external systems. Its like the serving station where the chef assembles the ingredients.
- Service Composition: Assembles domain components into complete workflow pipelines
- Transaction Boundaries: Manages unit-of-work patterns across multiple operations
- Interface Dependency: Operates exclusively against abstract ports, never concrete implementations
We organized this layer into two service families—api_services for synchronous request handling and event_services for asynchronous processing—creating a clean separation between different interaction patterns.
Infrastructure Layer: Concrete Implementations This outer layer contains all environment-specific code and external system integrations. This is like the operations team in a restaurant that takes care or reservations, client requests, supply-chain logistics. Its not sexy, but hell yeah is it useful. :)
- Port Implementations: Concrete adapters for each abstract interface
- External System Clients: Integration with databases, APIs, and compute resources
- Environment Configuration: Deployment-specific behavior and connection management
This layering discipline created unmistakable clarity in our codebase—every component has exactly one architectural responsibility, with dependencies flowing exclusively outward from domain to infrastructure.
Traditional vs. Hexagonal Architecture: Dependency Patterns Formalized
The distinction between traditional layered architecture and the Ports & Adapters pattern can be formalized as a difference in dependency graphs. Let me illustrate with a practical comparison:
In the traditional approach, domain logic directly depends on infrastructure implementations:
class PredictionEngine:
def __init__(self):
# Direct coupling to specific infrastructure
self.db_client = MongoClient("mongodb://localhost:27017/")
self.db = self.db_client["prediction_store"]
self.collection = self.db["model_predictions"]
def generate_prediction(self, features, model_id):
# Business logic intermixed with infrastructure concerns
if not self.collection.find_one({"model_id": model_id}):
raise ValueError(f"Unknown model: {model_id}")
# Direct dependency on storage details
model_config = self.collection.find_one({"model_id": model_id})
model = self._load_model(model_config["path"])
# Core algorithmic work mixed with persistence
prediction = model.predict(features)
prediction_id = self.collection.insert_one({
"model_id": model_id,
"features": features,
"result": prediction.tolist(),
"timestamp": datetime.now()
}).inserted_id
return {"prediction_id": str(prediction_id), "result": prediction}
The Ports & Adapters pattern establishes a formal dependency inversion, creating a directed acyclic graph of dependencies flowing outward from domain logic, showing the concepts above now in code.
# Domain Layer - Abstract interfaces as formal contracts
from typing import Protocol, Dict, Any, Optional, List
class ModelRepositoryInterface(Protocol):
"""Abstract model storage operations"""
def get_model_config(self, model_id: str) -> Optional[Dict[str, Any]]:
"""Retrieve model configuration by ID"""
...
def save_prediction(self, prediction_data: Dict[str, Any]) -> str:
"""Store prediction results and return identifier"""
...
class ModelLoaderInterface(Protocol):
"""Abstract model loading operations"""
def load_model(self, model_path: str) -> Any:
"""Load model from specified path"""
...
def predict(self, model: Any, features: List[float]) -> List[float]:
"""Generate prediction using model"""
...
# Service Layer - Pure logic
class PredictionEngineService:
def __init__(self, repository: ModelRepositoryInterface, loader: ModelLoaderInterface):
# Dependencies on abstractions establish formal boundary
self.repository = repository
self.loader = loader
def generate_prediction(self, features: List[float], model_id: str) -> Dict[str, Any]:
# Business logic independent of infrastructure details
model_config = self.repository.get_model_config(model_id)
if not model_config:
raise ValueError(f"Unknown model: {model_id}")
# Domain operations use abstract interfaces
model = self.loader.load_model(model_config["path"])
prediction = self.loader.predict(model, features)
# Persistence through abstract contract
prediction_id = self.repository.save_prediction({
"model_id": model_id,
"features": features,
"result": prediction,
"timestamp": datetime.now()
})
return {"prediction_id": prediction_id, "result": prediction}
This architectural creates two key properties for the system:
- Substitution invariance: Any implementation satisfying the interface contract can be substituted without affecting domain behavior
- Compositional reasoning: System behavior can be analyzed through the composition of well-defined components with clear boundaries
The immediate practical benefits include:
- Testability through isolation: Domain logic can be verified independently of infrastructure
- Implementation polymorphism: Multiple concrete adapters can satisfy the same interface contract
- Topological decoupling: Changes in infrastructure components don't propagate to domain logic
Refactoring Strategy
The challenge I faced was implementing these principles on a live codebase. Here are some of my notes of what worked:
Defining Domain Interfaces
The first step is defining clean interfaces that represent infrastructure requirements. This layer defines what the application needs from external systems without specifying how those needs are fulfilled.
As a first approximation, it simply means taking your existing core module and dividing the infrastructural concerns and its core functionality. The infrastructural concerns need to move out, the rest can stay.
This approach creates a strong contract— a reliable set of operations that must be satisfied by any concrete implementation.
class ISimulator(ABC):
"""Port interface for Simulation Services"""
@abstractmethod
async def run_simulation(self, experiment_id: str, parameters: dict) -> dict:
... # Define the methods the domain needs for simulation
Creating Adapters for Different Environments
For each port, we implement multiple adapters tailored to different environments. For the refactor, we first focused on simple adaptors that can run locally. This enabled us to validate the system-level implementations without worrying about the other details.
class PrefectSimulationRunnerService(ISimulator):
"""Adapter for running simulations using Prefect"""
def __init__(self):
self.simulator = Simulator() # Core simulation logic
async def run_simulation(self, experiment_id: str, parameters: dict) -> dict:
# Implementation for production environment
...
class LocalSimulationRunnerService(ISimulator):
"""Adapter for running simulations locally"""
# Implementation for local environment
...
class MockSimulationRunnerService(ISimulator):
"""Mock Adapter for testing purposes"""
# Implementation for testing environment
...
Application Services: Orchestrating Use Cases
The Application Layer orchestrates the use cases of our application by coordinating domain entities and services. It's responsible for translating between domain and external formats and managing workflows. The key difference is that Application Services depend only on abstract interfaces, not concrete implementations.
# In backend/application/simulation_service.py
class APIServices:
def __init__(
self,
atlas_service: IAtlas,
simulation_service: ISimulator,
notification_service: INotification
):
self.atlas_service = atlas_service
self.simulation_service = simulation_service
self.notification_service = notification_service
async def run_experiment(self, experiment_id: str, parameters: dict):
# 1. Get necessary data from the Atlas service
atlas_data = await self.atlas_service.get_atlas_data(experiment_id)
# 2. Combine with parameters and run simulation
enriched_parameters = {**parameters, "atlas_data": atlas_data}
simulation_result = await self.simulation_service.run_simulation(
experiment_id,
enriched_parameters
)
# 3. Notify relevant stakeholders
await self.notification_service.notify(
"experiment.completed",
{
"experiment_id": experiment_id,
"status": simulation_result.get("status", "unknown"),
"summary": simulation_result.get("summary", {})
}
)
return {
"experiment_id": experiment_id,
"result": simulation_result,
"status": "completed"
}
Dynamic Adapter Selection
One of the nice aspects of the Ports & Adapters architecture is the ability to switch between different implementations based on the environment. The added compexity of the interface now becomes its strength and actually simplifies configurations.
The system dynamically selects appropriate adapters based on the environment with a simple profiler factory:
class Environment(Enum):
DEVELOPMENT = "development"
STAGING = "staging"
PRODUCTION = "production"
TESTING = "testing"
LOCAL = "local"
class ServiceImplementations:
"""Maps service names to implementation classes for each environment"""
IMPLEMENTATIONS = {
Environment.PRODUCTION.value: {
"simulation": "backend.infrastructure.adapters.simulation_adapters.PrefectSimulationRunnerService",
"atlas": "backend.infrastructure.adapters.atlas_adapters.AtlasDBService",
"notification": "backend.infrastructure.adapters.notification_adapters.SlackNotificationService",
},
Environment.DEVELOPMENT.value: {
"simulation": "backend.infrastructure.adapters.simulation_adapters.LocalSimulationRunnerService",
"atlas": "backend.infrastructure.adapters.atlas_adapters.AtlasFileService",
"notification": "backend.infrastructure.adapters.notification_adapters.ConsoleNotificationService",
},
...
}
# Service instance cache
_service_instances: Dict[str, Any] = {}
def get_service_implementation(service_name: str) -> Any:
"""Factory function to get appropriate service implementation based on environment"""
# Return cached instance if available
if service_name in _service_instances:
return _service_instances[service_name]
# Determine current environment
environment = os.getenv("ENVIRONMENT", Environment.DEVELOPMENT.value)
# Get implementation class path
implementations = ServiceImplementations.IMPLEMENTATIONS.get(
environment,
ServiceImplementations.IMPLEMENTATIONS[Environment.DEVELOPMENT.value]
)
implementation_path = implementations.get(service_name)
if not implementation_path:
raise ValueError(f"No implementation defined for service '{service_name}' in environment '{environment}'")
# Import and instantiate implementation
module_path, class_name = implementation_path.rsplit(".", 1)
module = importlib.import_module(module_path)
service_class = getattr(module, class_name)
# Cache and return instance
_service_instances[service_name] = service_class()
return _service_instances[service_name]
This environment-aware factory approach gaveus tremendous flexibility.
- In production, we use robust, scalable implementations.
- In development, we use simpler, local implementations.
- In testing, we use mock implementations that don't require any external dependencies.
- ... All this happens without changing a single line of business logic.
End Notes
So. The implementation of Ports and Adapters architecture was delivered with some intense keyboard action, but several immediate benefits immediately emerged such as...
- Testing Without Infrastructure: Unit tests now run independently of external services, enabling proper CICD
- Diagnostic Precision: Issues can be isolated to specific layers and components
- Deployment Flexibility: The same core logic runs locally or in any cloud environment
- Enhanced Modularity: System components can be evolved independently
This felt good.
Though powerful, this architecture wasn't without costs:
- Increased Initial Complexity: More interfaces and abstractions to manage. It took a focused effort to refactor existing code to have this new layer, but it is doable without changing much at the service layer
- Debugging Indirection: Stack traces cross more layers and classes. It is better to make strong unit tests for each concrete implementation.
- Testing Discipline: Mock implementations must accurately simulate production behavior
Overall, am I glad we did this? 100% Yes.
The beauty of this is how it created a system for growth. Instead of brute-force free-for-alls, this system enabled engineers to collaborate through systems instead of endless video calls and documents.
"No, we DON'T have time to get on a quick call..."
Deep Dives
Ensuring Data Integrity Through Type-Safe Abstractions
One critical challenge in ML systems is ensuring consistent data representation across processing stages. Particularly in performance-sensitive domains where incorrect transformations can lead to costly errors, I needed abstractions that provide both safety and performance. The approach I advocated for applies functional programming principles to dataframe operations while maintaining vectorized performance.
The Problem: Performance & Typesafety
Working with tabular data introduces a fundamental tension between:
- Type safety: Ensuring columns contain expected types and conform to schema
- Vectorized performance: Maintaining the computational efficiency of numerical operations
- API consistency: Providing a familiar interface for data scientists
Solution: Type-Safe Schema Definition with Runtime Verification
Our approach uses formal data types to model schema constraints, eschewing any 3rd party implementations.
Instead, I relied on simple Enums and ABCs:
class SimulationColumn(Enum):
"""Enum defining simulation columns with their names and types"""
TIME = ("time", float)
CONCENTRATION = ("concentration", float)
TEMPERATURE = ("temperature", float)
PRESSURE = ("pressure", float)
@property
def name(self) -> str:
"""Get column name"""
return self.value[0]
@property
def dtype(self) -> type:
"""Get column data type"""
return self.value[1]
@classmethod
def all_columns(cls) -> List[str]:
"""Get all column names"""
return [col.name for col in cls]
@classmethod
def schema_items(cls) -> List[Tuple[str, type]]:
"""Get all column name-type pairs"""
return [col.value for col in cls]
# Abstract interface establishing contract for dataframes
class SimulationDataFrameInterface(ABC):
"""Abstract interface for dataframes containing simulation data"""
@abstractmethod
def has_required_columns(self) -> bool:
"""Check if dataframe has all required columns"""
pass
@abstractmethod
def validate_schema(self) -> bool:
"""Validate dataframe schema against requirements"""
pass
@abstractmethod
def get_data(self) -> pd.DataFrame:
"""Return the underlying DataFrame"""
pass
class EnhancedSimulationDataFrame(SimulationDataFrameInterface):
"""DataFrame implementation that conforms to the simulation interface"""
def __init__(self, data: pd.DataFrame):
"""Initialize with a pandas DataFrame"""
self._data = data
self._validate_on_init()
# ...validation implementation details...
def get_data(self) -> pd.DataFrame:
"""Return the underlying DataFrame"""
return self._data
# Domain function that uses the interface
def analyze_simulation_results(df: SimulationDataFrameInterface) -> dict:
"""Analyze simulation results with guaranteed schema compliance"""
data = df.get_data()
# Safe to access columns using enum properties
avg_conc = data[SimulationColumn.CONCENTRATION.name].mean()
max_temp = data[SimulationColumn.TEMPERATURE.name].max()
return {
"average_concentration": avg_conc,
"maximum_temperature": max_temp,
"data_points": len(data)
}
This approach provides several quantifiable benefits:
- Error Detection at Interface Boundaries: Schema violations are caught immediately at construction time rather than during computation, reducing debugging complexity by O(n) where n is the number of transformations applied
- Referential Transparency: Functions operating on validated dataframes maintain referential transparency, enabling formal reasoning about data transformations
- Computation Graph Optimization: With guaranteed schema compliance, computation graphs can be optimized knowing column types and presence
The performance overhead of validation is O(k) where k is the number of columns, which is typically negligible compared to the O(m×n) operations performed on dataframes where m is the row count. For our production system, this validation added overhead while eliminating an entire class of runtime errors.
For downstream engineers who used this patter, it gave several nice guarantees:
- Type Soundness: Operations within domain functions can't violate type constraints established by the schema
- Schema Invariance: Transformations preserve schema validity across function boundaries
- Composition Safety: Function compositions maintain schema constraints, enabling safe pipeline construction
Finally, this approach extends naturally to ML feature pipelines and model inputs, where type and shape consistency are critical. By applying the same pattern to feature transformations, we could ensure that features conform to the expected distribution and type, model inputs are guaranteed to match training schema and prediction outputs maintained consistent structure. It was a very nice benefit that did not required any additional work.
For our quantitative platform, this provided crucial guarantees about the validity of numerical operations throughout the processing pipeline, reducing model risk without sacrificing computational performance.
Future-proofing: Event Driven Architecture Migration Plan
The planning of this made it evident that the Ports & Adapters architecture provides an excellent foundation for transitioning to event-driven design.
By defining event-related interfaces in our domain, we abstract away the details of how events are published and consumed, allowing us to implement different event mechanisms in different environments.
At the service layer, we can define two kinds of services: api_services and event_services. Eventually, api_services will add items to the event queue: a simple but elegent transition for an active codebase!
Here's an example for complex operations like model training, we can extend the pattern to support event-driven workflows to enable a Asynchronous Processing Pattern:
# In backend/domain/ports/event_port.py
class IEventService(Protocol):
"""Port interface for event publishing and subscription"""
async def publish(self, event_type: str, payload: dict) -> None:
"""Publish an event with the given type and payload"""
...
async def subscribe(self, event_type: str, handler: Callable) -> Any:
"""Subscribe to events of the given type"""
...
Some Concrete Implementations
# In backend/infrastructure/adapters/event_adapters.py
class KafkaEventService(EventServiceProtocol):
"""Production-ready Kafka implementation of the event service"""
def __init__(self, bootstrap_servers):
from kafka import KafkaProducer, KafkaConsumer
self.producer = KafkaProducer(
bootstrap_servers=bootstrap_servers,
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
self.bootstrap_servers = bootstrap_servers
self.consumers = {}
async def publish(self, event_type: str, payload: dict) -> None:
"""Publish event to Kafka topic"""
self.producer.send(event_type, payload)
async def subscribe(self, event_type: str, handler: callable) -> Any:
"""Subscribe to Kafka topic"""
from kafka import KafkaConsumer
import threading
consumer = KafkaConsumer(
event_type,
bootstrap_servers=self.bootstrap_servers,
value_deserializer=lambda v: json.loads(v.decode('utf-8'))
)
def consumer_thread():
for message in consumer:
handler(message.value)
thread = threading.Thread(target=consumer_thread, daemon=True)
thread.start()
self.consumers[event_type] = (consumer, thread)
return thread
class InMemoryEventService(EventServiceProtocol):
"""Simple in-memory implementation for development and testing"""
def __init__(self):
self.subscribers = {}
async def publish(self, event_type: str, payload: dict) -> None:
"""Publish event to in-memory subscribers"""
if event_type in self.subscribers:
for handler in self.subscribers[event_type]:
await handler(payload)
async def subscribe(self, event_type: str, handler: callable) -> Any:
"""Subscribe to in-memory events"""
if event_type not in self.subscribers:
self.subscribers[event_type] = []
self.subscribers[event_type].append(handler)
return len(self.subscribers[event_type]) - 1
This approach allows us to use messaging infrastructure in production while keeping development and testing simple with in-memory event handling. The business logic remains unchanged, as it depends only on the abstract EventServiceProtocol.
class MLFlowDaedelusService(IDaedelusService):
def __init__(self, event_bus: IBusinessEventService):
self.event_bus = event_bus
def train_model_async(self, model_config: ModelConfig):
# Start asynchronous training task
background_task = run_long_training(model_config)
# Publish event on completion
def on_training_complete(results):
self.event_bus.publish(
"model_training_completed",
{"model_id": model_config.model_id, "results": results}
)
background_task.add_done_callback(on_training_complete)
return background_task
This pattern creates a composition where outputs from one operation become inputs to another, independent of timing constraints.
... or at least thats what it does in my head....