
Building an Article Summarizer for Enhancing Comprehension (1/2)
Building an Article Summarizer for Enhancing Comprehension (1/2)
Building an Article Summarizer for Enhancing Comprehension (1/2)
tl;dr:
An exploratory approach to article summarization that pairs knowledge graphs & large transformer models
Motivation
Sometimes we come across articles or documents that are difficult to understand, especially if they're outside our area of expertise. This common experience sparked the idea for this project.
My goal with this project was twofold: First, to deepen my understanding of transformer models and natural language processing (NLP) as part of my computing coursework. Second, to tackle a problem I'm sure many of us have encountered - making sense of complex, domain-specific articles.
This project, in essence, is about creating a way to simplify scientific or industry articles into something more digestible. It is meant as a tool to bridge the gap between expert knowledge and layperson understanding.
Hypotheses
This is variant of abstractive summarization. The project takes a novel approach and treats abstractive summarization as two distinct components: knowledge extraction and text generation. This strategy allows us to harness the capabilities of LLMs while maintaining a level of control and interpretability over the output.

The crux of our method revolves around mining essential information in the form of Subject-Verb-Object (SVO) triplets from the corpus. Following this, we employ 3 different transformer models, specifically T5, BERT, and GPT, to generate a coherent narrative using these triplets.
The model’s modular nature allows us to harness the strengths of non-neural and neural methods, facilitating the training of specialized modules and providing a framework to interpret and explain the results.
Dataset
This project works with the BBC News Summary dataset as the corpus for our study due to its well-formatted and simple nature, with model handcrafted summaries to evaluate against. This dataset was created by re-purposing the BBC News dataset originally created for benchmarks in classification.
Text Distillation
The core hypothesis of this first part is that the semantic essence of a text can be represented through a series of interconnected and interdependent subject-verb-object triplets, thus creating a graph of the information contained within the piece of text. This knowledge graph is to serve as “ground truth” for the downstream task of text summarization.
The text preparation stage of our pipeline involves several standard Natural Language Processing (NLP) tasks, including tokenization, stopword removal, stemming, and lemmatization. These procedures aid in distilling the corpus, reducing language variability, and aiding more efficient information extraction. Additionally, co-reference resolution is performed to facilitate accurate entity linking across the corpus and to retain the narrative structure within individual sentences, enhancing the fidelity of the extracted SVO triplets.
In an attempt to incorporate relevant context into the knowledge extraction phase, we posit that the title of an article could serve as a representative set of important terms. Consequently, keywords from the article title are extracted and incorporated into the entity recognition process. This step aims to improve the contextual relevance of named entities and aids in better aligning the knowledge extraction with the overall topic of the text.

Knowledge Graph Extraction
Our process of generating triplets follows a structure inspired by the WebNLG corpus, leveraging the RDF schema for knowledge representation. This structure provides us with a rich source of training data from the WebNLG corpus, which we later utilize for fine-tuning our language generation models.
We follow a procedure that parses the dependency structure of the text and applies a series of heuristics to extract Subject-Verb-Object (SVO) triplets. Here is an overview of the considerations:
Sentence Parsing: We parse the input text on a sentence level.
Verb-Subject-Object Initialization: We create a dictionary where verbs serve as keys, and sets of associated subjects and objects as their corresponding values.
Token Analysis: Each token in the sentences is analyzed based on its dependency label and part-of-speech tag.
Role Assignment: Depending on the dependency label, a token is assigned as a subject or an object and accordingly added to the Verb-SVO dictionary. Subjects can be nouns or subordinate clauses, while objects can be nouns, entities introduced by a preposition, or subordinate clauses.
Role Expansion: We expand subjects and objects to include related tokens such as compound nouns, conjuncts, or tokens within a clause, utilizing the subtree of each token.
Verb Conjuncts: We account for cases where multiple verbs are linked via conjunction (e.g., the sentence ”I read and wrote this book”), and update the dictionary accordingly, considering that such verbs share the same subjects and objects.
SVO Triplet Extraction: The extracted triplets are retrieved from the Verb-SVO dictionary, each triplet represented as a tuple in the order of subject-verb-object.
In the process of triplet extraction, we have devised two variations - 'greedy' and 'strict'. These variations differ in steps 5 and 7.
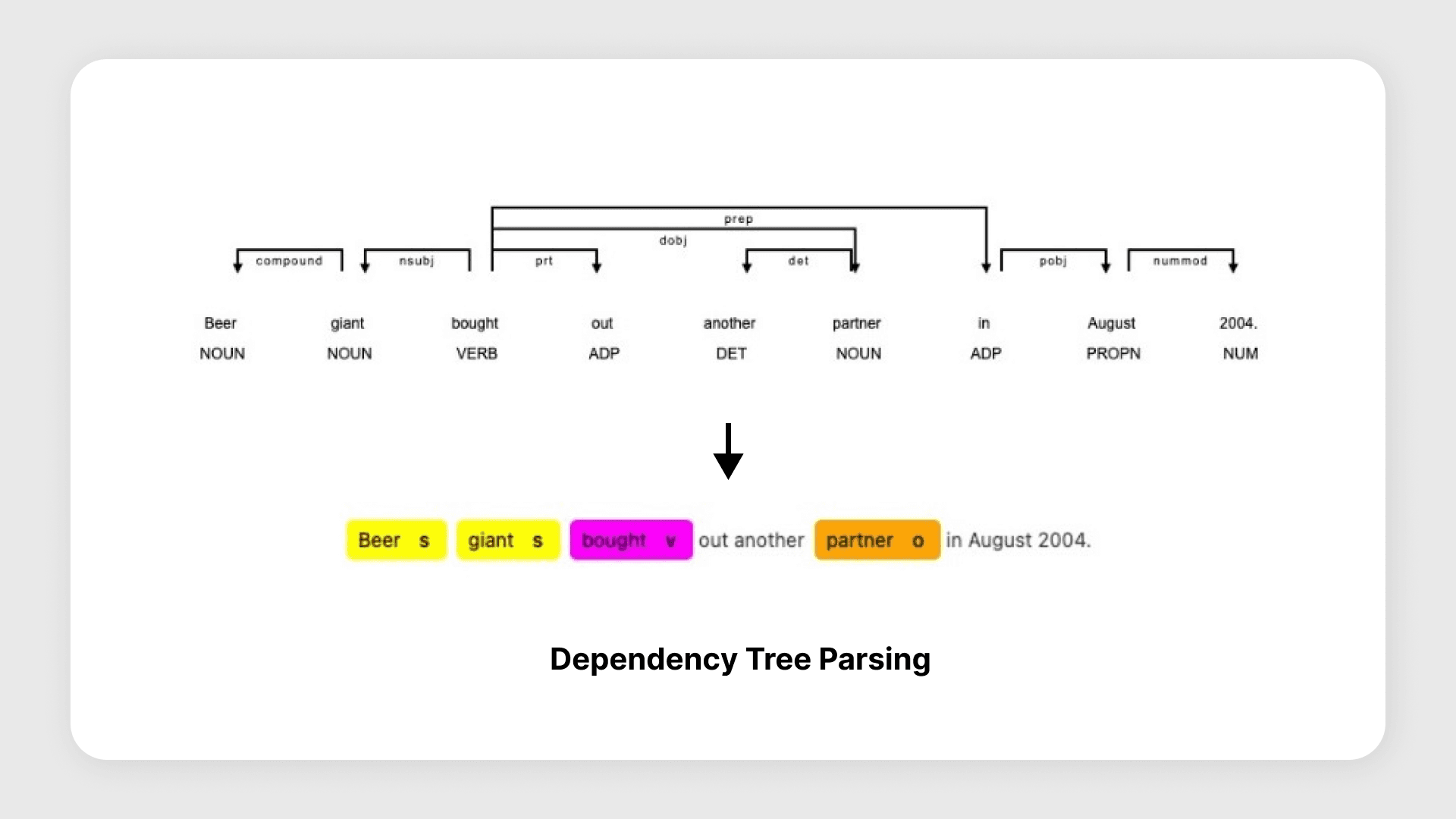
In the 'greedy' implementation, we liberally follow token chains during subject and object expansion (step 5), which results in longer and more contextually rich SVO triplets. We also relax the criteria in step 7 to permit non-entity and non-verb tokens in the subject and verb positions.
Conversely, the 'strict' implementation focuses on the extraction of 'essential' triples. We cap token chains to a maximum of five tokens and exclude auxiliary verbs. In step 7, we restrict non-entity and non-verb tokens, with the exception for subjects and objects that originated from the title. All non-entities are then subjected to lemmatization.
Final Thoughts
The knowledge extraction stage of this project was challenging in a fun way. While it did convert complex articles into structured SVO triplets, it also revealed some gaps and areas for enhancement:
Context & Nuance- The current reliance on syntactic structures and heuristics failed to capture some nuanced meanings, such as those embedded in context, metaphor, or sarcasm. The process also struggled with texts where important information is not easily reducible to simple SVO triplets.
Semantic Boundaries - What is the boundary of relationships in a text? In the above process, triplets are generated from relationships within a sentence. While co-reference resolution will help somewhat, there will still be meaningful relationships that will be lost.
Sensitivity - The 'greedy' and 'strict' variations of triplet extraction present a trade-off between capturing rich context and maintaining precision, raising the opportunity to find the optimal balance.
Future improvements might include maintaining a “master graph” for the knowledge domain so it can be enriched with useful facts… but we have enough for now to continue.
The next part of this project will focus on text generation, building upon the structured data from the knowledge extraction phase. The varying outcomes of different transformer architectures will offer an perspective on the capabilities of modern NLP technology.
Appendix: Code Snippets
Here are some code snippets for the various procedures. Code was written in Python and uses SpaCy.
Tokenizer and Tagger Functions
##########################################################################################################################################
# TOKENIZER AND TAGGER
# helper functions
##########################################################################################################################################
def tag_and_tokenize_keywords(doc):
# Create a lemmatized version of the input document
matcher_ent = spacy.matcher.PhraseMatcher(nlp.vocab, attr="LEMMA")
matcher_other = spacy.matcher.PhraseMatcher(nlp.vocab, attr="LOWER")
patterns_ent = [nlp(keyword) for keyword in keywords[0]]
patterns_other = [nlp.make_doc(keyword) for keyword in keywords[1]]
matcher_ent.add("KEYWORD_ENT", patterns_ent)
matcher_other.add("KEYWORD_OTHER", patterns_other)
lemmatized_doc = nlp(" ".join([token.lemma_ for token in doc]))
# Retokenize the document to merge multi-token keyword spans
with doc.retokenize() as retokenizer:
# Iterate through the matchers (matcher_ent, matcher_other) and their target documents (lemmatized_doc, doc)
for matcher, target_doc in zip([matcher_ent, matcher_other], [lemmatized_doc, doc]):
# Find matches in the target document using the current matcher
for match_id, start, end in matcher(target_doc):
# Create a span in the original document corresponding to the matched keywords
span = doc[start:end]
# Merge the span into a single token
retokenizer.merge(span)
# Set the 'is_keyword' and 'custom_tag' attributes for the merged token
span[0].set_extension("is_keyword", default=False, force=True)
span[0]._.is_keyword = True
span[0].set_extension("custom_tag", default=None, force=True)
span[0]._.custom_tag = nlp.vocab.strings[match_id]
return doc
def add_keywords_to_ents(doc):
new_ents = []
for token in doc:
if token._.is_keyword:
new_ent = spacy.tokens.Span(doc, token.i, token.i + 1, label=token._.custom_tag)
new_ents.append(new_ent)
# Filter out existing entities that overlap with the new keyword entities
filtered_ents = []
for ent in doc.ents:
overlaps = [ent.start <= new_ent.start < ent.end or new_ent.start <= ent.start < new_ent.end for new_ent in new_ents]
if not any(overlaps):
filtered_ents.append(ent)
doc.set_ents(filtered_ents + new_ents)
return doc
def convert_entities_to_tokens(doc):
with doc.retokenize() as retokenizer:
for ent in doc.ents:
# Create a span for the current entity
span = doc[ent.start:ent.end]
# Merge the span into a single token
retokenizer.merge(span)
return doc
def merge_noun_chunks(doc):
with doc.retokenize() as retokenizer:
for np in list(doc.noun_chunks):
retokenizer.merge(np)
return doc
def merge_symb2num(doc):
"""
Merge adjacent currency symbol and number tokens.
"""
i = 1
while i < len(doc):
if doc[i].is_digit and doc[i - 1].is_currency:
span = doc[doc[i - 1].i: doc[i].i + 1]
with doc.retokenize() as retokenizer:
retokenizer.merge(span)
else:
i += 1
return doc
# Displacy Formatting
col_highlight1 = "magenta"
col_highlight2 = "yellow"
col_others = "lightblue"
options_ent = {
"ents": ["KEYWORD_ENT", "KEYWORD_OTHER",
"ORG", "PRODUCT", "GPE", "LOC", "PERSON", "FAC", "NORP", "DATE", "TIME", "PERCENT", "MONEY", "QUANTITY", "ORDINAL", "CARDINAL", "LANGUAGE", "EVENT", "LAW", "WORK_OF_ART"],
"colors": {"KEYWORD_ENT": col_highlight1,
"KEYWORD_OTHER": col_highlight2,
"ORG": col_others,
"PRODUCT": col_others,
"GPE": col_others,
"LOC": col_others,
"PERSON": col_others,
"FAC": col_others,
"NORP": col_others,
"DATE": col_others,
"TIME": col_others,
"PERCENT": col_others,
"MONEY": col_others,
"QUANTITY": col_others,
"ORDINAL": col_others,
"CARDINAL": col_others,
"LANGUAGE": col_others,
"EVENT": col_others,
"LAW": col_others,
"WORK_OF_ART": col_others}
}
options_dep = {'compact': True, 'color': 'black', 'bg': 'white', 'offset': 100, 'distance': 100, 'font': 'Arial'}
##########################################################################################################################################
# Process Sampling
##########################################################################################################################################
# Generate Sample
doc_idx = 368
title = seperate_title_and_body(articles[doc_idx])[0]
body = seperate_title_and_body(articles[doc_idx])[1]
keywords = article_keywords[doc_idx]
print("title: ", title)
print("title keywords: ", keywords)
print("body: ", body)
# Create new NLP instances, incl matchers
nlp = spacy.load("en_core_web_lg")
matcher_ent = spacy.matcher.PhraseMatcher(nlp.vocab, attr="LEMMA")
matcher_other = spacy.matcher.PhraseMatcher(nlp.vocab, attr="LOWER")
patterns_ent = [nlp(keyword) for keyword in keywords[0]]
patterns_other = [nlp.make_doc(keyword) for keyword in keywords[1]]
matcher_ent.add("KEYWORD_ENT", patterns_ent)
matcher_other.add("KEYWORD_OTHER", patterns_other)
# Pipeline the inputs
doc = nlp(body)
doc = tag_and_tokenize_keywords(doc)
doc = add_keywords_to_ents(doc)
# doc = convert_entities_to_tokens(doc)
# doc = merge_noun_chunks(doc)
# doc = merge_symb2num(doc)
# spacy.displacy.render(doc, style = "dep")
spacy.displacy.render(doc, style = "dep", options = options_dep)
spacy.displacy.render(doc, style = "ent", options = options_ent)
Sample Output

Text Corpus with extracted keywords. Colour coded highlights indicate keyword tag.
Subject-Verb-Object Extraction Functions
##########################################################################################################################################
# SUBJECT-VERB-OBJECT EXTRACTION
# Helper Functions
##########################################################################################################################################
# The following generates triples regardless of keywords.
# See ref: https://textacy.readthedocs.io/en/latest/api_reference/extract.html#triples
def generate_triplet2sentence_pairs(doc, arr_keyword, return_type = 'std', keyword_filter = False, VERBOSE = False):
'''
Returns a list of tuple-pairs:
[(triple, sentence), (triple, sentence), ...]
Parameters:
-----------
doc : spacy.tokens.Doc
A SpaCy document containing the text to extract SVO triplets from.
arr_keyword : List[List[str]]
A nested list of keywords (strings), where each sublist represents a set of related keywords.
keyword_filter : bool, optional (default=False)
If True, only include triplets containing at least one keyword from the given keyword list.
VERBOSE : bool, optional (default=False)
If True, print additional information, such as the list of flattened keywords.
Returns:
--------
pairs : List[Tuple[str, spacy.tokens.Span]]
A list of tuple pairs, where each tuple contains a formatted triplet (as a string) and
the sentence.
Example usage:
--------------
keywords = ['Time Warner', 'sales', 'boost', 'profit']
svo_pairs = generate_triplet2sentence_pairs(doc, arr_keyword=keywords, keyword_filter=True,
'''
pairs = []
combined_data = []
# filtering, if it happens
flat_keywords = [item for sublist in arr_keyword for item in sublist]
if VERBOSE: print("flat keywords: ", flat_keywords)
# Iterate through sentences in the doc
for sent in doc.sents:
# Extract SVO triples for each sentence
triples = list(textacy.extract.subject_verb_object_triples(sent))
formatted_triples = []
for triple in triples:
###########################
# visualizer
###########################
if VERBOSE:
options = {'compact': True, 'color': 'black', 'bg': 'white', 'offset': 100, 'distance': 100, 'font': 'Arial'}
spacy.displacy.render(sent, style='dep', jupyter=True, options=options)
sent_start = sent[0].idx
entities_s = [{'start': t.idx - sent_start, 'end': t.idx - sent_start + len(t), 'label': 'S'} for t in triple[0]]
entities_v = [{'start': t.idx - sent_start, 'end': t.idx - sent_start + len(t), 'label': 'V'} for t in triple[1]]
entities_o = [{'start': t.idx - sent_start, 'end': t.idx - sent_start + len(t), 'label': 'O'} for t in triple[2]]
all_entities = entities_s + entities_v + entities_o
displacy_ex = [{'text': sent.text, 'ents': all_entities, 'title': None}]
spacy.displacy.render(displacy_ex, style='ent', jupyter=True, manual=True, options={'colors': {'S': 'yellow', 'V': 'magenta', 'O': 'orange'}})
###########################
# modify triplets
###########################
# for s, v, o, print their entity types
if VERBOSE:
for svo in triple:
for tok in svo:
if hasattr(tok, "ent_id"):
print(tok, " : ", tok.ent_type_)
for svo in triple:
for idx, tok in enumerate(svo[:-1]):
# drop if its AUX
if tok.pos_ == "AUX":
# drop from v_toks
svo.remove(tok)
# drop if its PART
if tok.pos_ == "PART":
# drop from v_toks
svo.remove(tok)
# if entity = money, include the prceeding token if its a symbol. new token should be put in front of the token
if tok.ent_type_ == "MONEY" and tok.nbor(-1).pos_ == "SYM":
# check if the token to the left of tok is already in the list
if idx > 0 and svo[idx-1] == tok.nbor(-1):
continue
svo.insert(idx - 1, tok.nbor(-1))
# FIXME - if token's child is linked to it by a possesive modifier, replace the token with the child
# has_poss_child = any(child.dep_ == "poss" for child in tok.children)
# if has_poss_child:
# print("POSS FOUND: ", tok, " : ", tok.children[0])
# svo[idx] = tok.children[0]
###########################
# reject triples
###########################
# Final check: only proceed if subject, verb or object have less than 5 tokens each
if len(triple[0]) > 5 or len(triple[1]) > 5 or len(triple[2]) > 5:
if VERBOSE: print("REJECT: Triple is too long. Passing")
continue
# reject subject is it is not an entity or noun
if (not any([tok.ent_type_ for tok in triple[0]]) and not any([tok.pos_ == "NOUN" for tok in triple[0]])):
if VERBOSE: print("REJECT: Subject does not have entity type or is not a noun. Passing")
continue
# reject object is it is not an entity or noun
# if (not any([tok.ent_type_ for tok in triple[2]]) and not any([tok.pos_ == "NOUN" for tok in triple[2]])):
# if VERBOSE: print("REJECT: Object does not have entity type or is not a noun. Passing")
# continue
if VERBOSE:
print(f"processed: {[tok.text for tok in triple[0]], [tok.text for tok in triple[1]], [tok.text for tok in triple[2]]}")
###########################
# final formatting
###########################
subject = []
verb = []
obj = []
for tok in triple[0]:
if tok.ent_type_ and tok.ent_type_ != "KEYWORD_OTHER":
subject.append(tok.text)
else:
subject.append(tok.lemma_)
for tok in triple[1]:
if tok.ent_type_:
verb.append(tok.text)
else:
verb.append(tok.lemma_)
for tok in triple[2]:
if tok.ent_type_ and tok.ent_type_ != "KEYWORD_OTHER":
obj.append(tok.text)
else:
obj.append(tok.lemma_)
if keyword_filter:
# Check if any keyword is present in the subject, verb, or object
if not any(keyword in subject + verb + obj for keyword in flat_keywords):
continue
formatted_triples = f"{'_'.join(subject)} | {'_'.join(verb)} | {'_'.join(obj)}"
# store to main lists
pairs.append((formatted_triples, sent.text))
combined_data.append(formatted_triples + " <==> " + sent.text)
if VERBOSE: print("added: ", formatted_triples)
if return_type == "std":
return pairs
if return_type == "llm":
return combined_data
##########################################################################################################################################
# Process Sampling
##########################################################################################################################################
keywords = article_keywords[doc_idx]
# print(keywords)
pairs = generate_triplet2sentence_pairs(doc, arr_keyword = keywords, keyword_filter = False, VERBOSE= True)
print ([a for a,b in pairs])
Sample Output
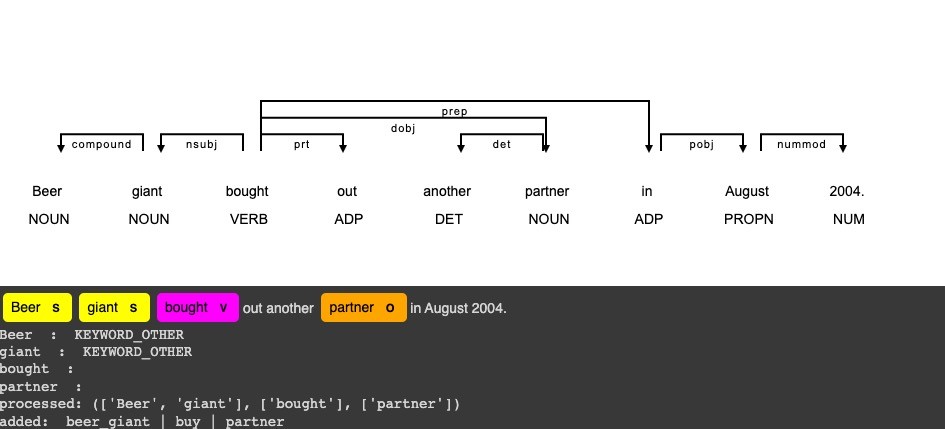
Tagged sentence with extracted triplet.
Github Repo: https://github.com/lennardong/article_summarizer/tree/main
Motivation
Sometimes we come across articles or documents that are difficult to understand, especially if they're outside our area of expertise. This common experience sparked the idea for this project.
My goal with this project was twofold: First, to deepen my understanding of transformer models and natural language processing (NLP) as part of my computing coursework. Second, to tackle a problem I'm sure many of us have encountered - making sense of complex, domain-specific articles.
This project, in essence, is about creating a way to simplify scientific or industry articles into something more digestible. It is meant as a tool to bridge the gap between expert knowledge and layperson understanding.
Hypotheses
This is variant of abstractive summarization. The project takes a novel approach and treats abstractive summarization as two distinct components: knowledge extraction and text generation. This strategy allows us to harness the capabilities of LLMs while maintaining a level of control and interpretability over the output.
The crux of our method revolves around mining essential information in the form of Subject-Verb-Object (SVO) triplets from the corpus. Following this, we employ 3 different transformer models, specifically T5, BERT, and GPT, to generate a coherent narrative using these triplets.
The model’s modular nature allows us to harness the strengths of non-neural and neural methods, facilitating the training of specialized modules and providing a framework to interpret and explain the results.
Dataset
This project works with the BBC News Summary dataset as the corpus for our study due to its well-formatted and simple nature, with model handcrafted summaries to evaluate against. This dataset was created by re-purposing the BBC News dataset originally created for benchmarks in classification.
Text Distillation
The core hypothesis of this first part is that the semantic essence of a text can be represented through a series of interconnected and interdependent subject-verb-object triplets, thus creating a graph of the information contained within the piece of text. This knowledge graph is to serve as “ground truth” for the downstream task of text summarization.
The text preparation stage of our pipeline involves several standard Natural Language Processing (NLP) tasks, including tokenization, stopword removal, stemming, and lemmatization. These procedures aid in distilling the corpus, reducing language variability, and aiding more efficient information extraction. Additionally, co-reference resolution is performed to facilitate accurate entity linking across the corpus and to retain the narrative structure within individual sentences, enhancing the fidelity of the extracted SVO triplets.
In an attempt to incorporate relevant context into the knowledge extraction phase, we posit that the title of an article could serve as a representative set of important terms. Consequently, keywords from the article title are extracted and incorporated into the entity recognition process. This step aims to improve the contextual relevance of named entities and aids in better aligning the knowledge extraction with the overall topic of the text.
Knowledge Graph Extraction
Our process of generating triplets follows a structure inspired by the WebNLG corpus, leveraging the RDF schema for knowledge representation. This structure provides us with a rich source of training data from the WebNLG corpus, which we later utilize for fine-tuning our language generation models.
We follow a procedure that parses the dependency structure of the text and applies a series of heuristics to extract Subject-Verb-Object (SVO) triplets. Here is an overview of the considerations:
Sentence Parsing: We parse the input text on a sentence level.
Verb-Subject-Object Initialization: We create a dictionary where verbs serve as keys, and sets of associated subjects and objects as their corresponding values.
Token Analysis: Each token in the sentences is analyzed based on its dependency label and part-of-speech tag.
Role Assignment: Depending on the dependency label, a token is assigned as a subject or an object and accordingly added to the Verb-SVO dictionary. Subjects can be nouns or subordinate clauses, while objects can be nouns, entities introduced by a preposition, or subordinate clauses.
Role Expansion: We expand subjects and objects to include related tokens such as compound nouns, conjuncts, or tokens within a clause, utilizing the subtree of each token.
Verb Conjuncts: We account for cases where multiple verbs are linked via conjunction (e.g., the sentence ”I read and wrote this book”), and update the dictionary accordingly, considering that such verbs share the same subjects and objects.
SVO Triplet Extraction: The extracted triplets are retrieved from the Verb-SVO dictionary, each triplet represented as a tuple in the order of subject-verb-object.
In the process of triplet extraction, we have devised two variations - 'greedy' and 'strict'. These variations differ in steps 5 and 7.
In the 'greedy' implementation, we liberally follow token chains during subject and object expansion (step 5), which results in longer and more contextually rich SVO triplets. We also relax the criteria in step 7 to permit non-entity and non-verb tokens in the subject and verb positions.
Conversely, the 'strict' implementation focuses on the extraction of 'essential' triples. We cap token chains to a maximum of five tokens and exclude auxiliary verbs. In step 7, we restrict non-entity and non-verb tokens, with the exception for subjects and objects that originated from the title. All non-entities are then subjected to lemmatization.
Final Thoughts
The knowledge extraction stage of this project was challenging in a fun way. While it did convert complex articles into structured SVO triplets, it also revealed some gaps and areas for enhancement:
Context & Nuance- The current reliance on syntactic structures and heuristics failed to capture some nuanced meanings, such as those embedded in context, metaphor, or sarcasm. The process also struggled with texts where important information is not easily reducible to simple SVO triplets.
Semantic Boundaries - What is the boundary of relationships in a text? In the above process, triplets are generated from relationships within a sentence. While co-reference resolution will help somewhat, there will still be meaningful relationships that will be lost.
Sensitivity - The 'greedy' and 'strict' variations of triplet extraction present a trade-off between capturing rich context and maintaining precision, raising the opportunity to find the optimal balance.
Future improvements might include maintaining a “master graph” for the knowledge domain so it can be enriched with useful facts… but we have enough for now to continue.
The next part of this project will focus on text generation, building upon the structured data from the knowledge extraction phase. The varying outcomes of different transformer architectures will offer an perspective on the capabilities of modern NLP technology.
Appendix: Code Snippets
Here are some code snippets for the various procedures. Code was written in Python and uses SpaCy.
Tokenizer and Tagger Functions
##########################################################################################################################################
# TOKENIZER AND TAGGER
# helper functions
##########################################################################################################################################
def tag_and_tokenize_keywords(doc):
# Create a lemmatized version of the input document
matcher_ent = spacy.matcher.PhraseMatcher(nlp.vocab, attr="LEMMA")
matcher_other = spacy.matcher.PhraseMatcher(nlp.vocab, attr="LOWER")
patterns_ent = [nlp(keyword) for keyword in keywords[0]]
patterns_other = [nlp.make_doc(keyword) for keyword in keywords[1]]
matcher_ent.add("KEYWORD_ENT", patterns_ent)
matcher_other.add("KEYWORD_OTHER", patterns_other)
lemmatized_doc = nlp(" ".join([token.lemma_ for token in doc]))
# Retokenize the document to merge multi-token keyword spans
with doc.retokenize() as retokenizer:
# Iterate through the matchers (matcher_ent, matcher_other) and their target documents (lemmatized_doc, doc)
for matcher, target_doc in zip([matcher_ent, matcher_other], [lemmatized_doc, doc]):
# Find matches in the target document using the current matcher
for match_id, start, end in matcher(target_doc):
# Create a span in the original document corresponding to the matched keywords
span = doc[start:end]
# Merge the span into a single token
retokenizer.merge(span)
# Set the 'is_keyword' and 'custom_tag' attributes for the merged token
span[0].set_extension("is_keyword", default=False, force=True)
span[0]._.is_keyword = True
span[0].set_extension("custom_tag", default=None, force=True)
span[0]._.custom_tag = nlp.vocab.strings[match_id]
return doc
def add_keywords_to_ents(doc):
new_ents = []
for token in doc:
if token._.is_keyword:
new_ent = spacy.tokens.Span(doc, token.i, token.i + 1, label=token._.custom_tag)
new_ents.append(new_ent)
# Filter out existing entities that overlap with the new keyword entities
filtered_ents = []
for ent in doc.ents:
overlaps = [ent.start <= new_ent.start < ent.end or new_ent.start <= ent.start < new_ent.end for new_ent in new_ents]
if not any(overlaps):
filtered_ents.append(ent)
doc.set_ents(filtered_ents + new_ents)
return doc
def convert_entities_to_tokens(doc):
with doc.retokenize() as retokenizer:
for ent in doc.ents:
# Create a span for the current entity
span = doc[ent.start:ent.end]
# Merge the span into a single token
retokenizer.merge(span)
return doc
def merge_noun_chunks(doc):
with doc.retokenize() as retokenizer:
for np in list(doc.noun_chunks):
retokenizer.merge(np)
return doc
def merge_symb2num(doc):
"""
Merge adjacent currency symbol and number tokens.
"""
i = 1
while i < len(doc):
if doc[i].is_digit and doc[i - 1].is_currency:
span = doc[doc[i - 1].i: doc[i].i + 1]
with doc.retokenize() as retokenizer:
retokenizer.merge(span)
else:
i += 1
return doc
# Displacy Formatting
col_highlight1 = "magenta"
col_highlight2 = "yellow"
col_others = "lightblue"
options_ent = {
"ents": ["KEYWORD_ENT", "KEYWORD_OTHER",
"ORG", "PRODUCT", "GPE", "LOC", "PERSON", "FAC", "NORP", "DATE", "TIME", "PERCENT", "MONEY", "QUANTITY", "ORDINAL", "CARDINAL", "LANGUAGE", "EVENT", "LAW", "WORK_OF_ART"],
"colors": {"KEYWORD_ENT": col_highlight1,
"KEYWORD_OTHER": col_highlight2,
"ORG": col_others,
"PRODUCT": col_others,
"GPE": col_others,
"LOC": col_others,
"PERSON": col_others,
"FAC": col_others,
"NORP": col_others,
"DATE": col_others,
"TIME": col_others,
"PERCENT": col_others,
"MONEY": col_others,
"QUANTITY": col_others,
"ORDINAL": col_others,
"CARDINAL": col_others,
"LANGUAGE": col_others,
"EVENT": col_others,
"LAW": col_others,
"WORK_OF_ART": col_others}
}
options_dep = {'compact': True, 'color': 'black', 'bg': 'white', 'offset': 100, 'distance': 100, 'font': 'Arial'}
##########################################################################################################################################
# Process Sampling
##########################################################################################################################################
# Generate Sample
doc_idx = 368
title = seperate_title_and_body(articles[doc_idx])[0]
body = seperate_title_and_body(articles[doc_idx])[1]
keywords = article_keywords[doc_idx]
print("title: ", title)
print("title keywords: ", keywords)
print("body: ", body)
# Create new NLP instances, incl matchers
nlp = spacy.load("en_core_web_lg")
matcher_ent = spacy.matcher.PhraseMatcher(nlp.vocab, attr="LEMMA")
matcher_other = spacy.matcher.PhraseMatcher(nlp.vocab, attr="LOWER")
patterns_ent = [nlp(keyword) for keyword in keywords[0]]
patterns_other = [nlp.make_doc(keyword) for keyword in keywords[1]]
matcher_ent.add("KEYWORD_ENT", patterns_ent)
matcher_other.add("KEYWORD_OTHER", patterns_other)
# Pipeline the inputs
doc = nlp(body)
doc = tag_and_tokenize_keywords(doc)
doc = add_keywords_to_ents(doc)
# doc = convert_entities_to_tokens(doc)
# doc = merge_noun_chunks(doc)
# doc = merge_symb2num(doc)
# spacy.displacy.render(doc, style = "dep")
spacy.displacy.render(doc, style = "dep", options = options_dep)
spacy.displacy.render(doc, style = "ent", options = options_ent)
Sample Output
Text Corpus with extracted keywords. Colour coded highlights indicate keyword tag.
Subject-Verb-Object Extraction Functions
##########################################################################################################################################
# SUBJECT-VERB-OBJECT EXTRACTION
# Helper Functions
##########################################################################################################################################
# The following generates triples regardless of keywords.
# See ref: https://textacy.readthedocs.io/en/latest/api_reference/extract.html#triples
def generate_triplet2sentence_pairs(doc, arr_keyword, return_type = 'std', keyword_filter = False, VERBOSE = False):
'''
Returns a list of tuple-pairs:
[(triple, sentence), (triple, sentence), ...]
Parameters:
-----------
doc : spacy.tokens.Doc
A SpaCy document containing the text to extract SVO triplets from.
arr_keyword : List[List[str]]
A nested list of keywords (strings), where each sublist represents a set of related keywords.
keyword_filter : bool, optional (default=False)
If True, only include triplets containing at least one keyword from the given keyword list.
VERBOSE : bool, optional (default=False)
If True, print additional information, such as the list of flattened keywords.
Returns:
--------
pairs : List[Tuple[str, spacy.tokens.Span]]
A list of tuple pairs, where each tuple contains a formatted triplet (as a string) and
the sentence.
Example usage:
--------------
keywords = ['Time Warner', 'sales', 'boost', 'profit']
svo_pairs = generate_triplet2sentence_pairs(doc, arr_keyword=keywords, keyword_filter=True,
'''
pairs = []
combined_data = []
# filtering, if it happens
flat_keywords = [item for sublist in arr_keyword for item in sublist]
if VERBOSE: print("flat keywords: ", flat_keywords)
# Iterate through sentences in the doc
for sent in doc.sents:
# Extract SVO triples for each sentence
triples = list(textacy.extract.subject_verb_object_triples(sent))
formatted_triples = []
for triple in triples:
###########################
# visualizer
###########################
if VERBOSE:
options = {'compact': True, 'color': 'black', 'bg': 'white', 'offset': 100, 'distance': 100, 'font': 'Arial'}
spacy.displacy.render(sent, style='dep', jupyter=True, options=options)
sent_start = sent[0].idx
entities_s = [{'start': t.idx - sent_start, 'end': t.idx - sent_start + len(t), 'label': 'S'} for t in triple[0]]
entities_v = [{'start': t.idx - sent_start, 'end': t.idx - sent_start + len(t), 'label': 'V'} for t in triple[1]]
entities_o = [{'start': t.idx - sent_start, 'end': t.idx - sent_start + len(t), 'label': 'O'} for t in triple[2]]
all_entities = entities_s + entities_v + entities_o
displacy_ex = [{'text': sent.text, 'ents': all_entities, 'title': None}]
spacy.displacy.render(displacy_ex, style='ent', jupyter=True, manual=True, options={'colors': {'S': 'yellow', 'V': 'magenta', 'O': 'orange'}})
###########################
# modify triplets
###########################
# for s, v, o, print their entity types
if VERBOSE:
for svo in triple:
for tok in svo:
if hasattr(tok, "ent_id"):
print(tok, " : ", tok.ent_type_)
for svo in triple:
for idx, tok in enumerate(svo[:-1]):
# drop if its AUX
if tok.pos_ == "AUX":
# drop from v_toks
svo.remove(tok)
# drop if its PART
if tok.pos_ == "PART":
# drop from v_toks
svo.remove(tok)
# if entity = money, include the prceeding token if its a symbol. new token should be put in front of the token
if tok.ent_type_ == "MONEY" and tok.nbor(-1).pos_ == "SYM":
# check if the token to the left of tok is already in the list
if idx > 0 and svo[idx-1] == tok.nbor(-1):
continue
svo.insert(idx - 1, tok.nbor(-1))
# FIXME - if token's child is linked to it by a possesive modifier, replace the token with the child
# has_poss_child = any(child.dep_ == "poss" for child in tok.children)
# if has_poss_child:
# print("POSS FOUND: ", tok, " : ", tok.children[0])
# svo[idx] = tok.children[0]
###########################
# reject triples
###########################
# Final check: only proceed if subject, verb or object have less than 5 tokens each
if len(triple[0]) > 5 or len(triple[1]) > 5 or len(triple[2]) > 5:
if VERBOSE: print("REJECT: Triple is too long. Passing")
continue
# reject subject is it is not an entity or noun
if (not any([tok.ent_type_ for tok in triple[0]]) and not any([tok.pos_ == "NOUN" for tok in triple[0]])):
if VERBOSE: print("REJECT: Subject does not have entity type or is not a noun. Passing")
continue
# reject object is it is not an entity or noun
# if (not any([tok.ent_type_ for tok in triple[2]]) and not any([tok.pos_ == "NOUN" for tok in triple[2]])):
# if VERBOSE: print("REJECT: Object does not have entity type or is not a noun. Passing")
# continue
if VERBOSE:
print(f"processed: {[tok.text for tok in triple[0]], [tok.text for tok in triple[1]], [tok.text for tok in triple[2]]}")
###########################
# final formatting
###########################
subject = []
verb = []
obj = []
for tok in triple[0]:
if tok.ent_type_ and tok.ent_type_ != "KEYWORD_OTHER":
subject.append(tok.text)
else:
subject.append(tok.lemma_)
for tok in triple[1]:
if tok.ent_type_:
verb.append(tok.text)
else:
verb.append(tok.lemma_)
for tok in triple[2]:
if tok.ent_type_ and tok.ent_type_ != "KEYWORD_OTHER":
obj.append(tok.text)
else:
obj.append(tok.lemma_)
if keyword_filter:
# Check if any keyword is present in the subject, verb, or object
if not any(keyword in subject + verb + obj for keyword in flat_keywords):
continue
formatted_triples = f"{'_'.join(subject)} | {'_'.join(verb)} | {'_'.join(obj)}"
# store to main lists
pairs.append((formatted_triples, sent.text))
combined_data.append(formatted_triples + " <==> " + sent.text)
if VERBOSE: print("added: ", formatted_triples)
if return_type == "std":
return pairs
if return_type == "llm":
return combined_data
##########################################################################################################################################
# Process Sampling
##########################################################################################################################################
keywords = article_keywords[doc_idx]
# print(keywords)
pairs = generate_triplet2sentence_pairs(doc, arr_keyword = keywords, keyword_filter = False, VERBOSE= True)
print ([a for a,b in pairs])
Sample Output
Tagged sentence with extracted triplet.
Github Repo: https://github.com/lennardong/article_summarizer/tree/main